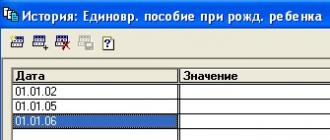
Запоминающее устройство с произвольным обращением, как правило, содержит множество одинаковых запоминающих элементов, образующих запоминающий массив (ЗМ). Массив разделен на отдельные ячейки; каждая из них предназначена для хранения двоичного кода, число разрядов в котором определяется шириной выборки памяти (в частности, это может быть одно, половина или несколько машинных слов). Способ организации памяти зависит от методов размещения и поиска информации в запоминающем массиве. По этому признаку различают адресную, ассоциативную и стековую (магазинную) памяти.
Адресная память. В памяти с адресной организацией размещение и поиск информации в ЗМ основаны на использовании адреса хранения слова (числа, команды и т. п.). Адресом служит номер ячейки ЗМ, в которой это слово размещается.
При записи (или считывании) слова в ЗМ инициирующая эту операцию команда должна указывать адрес (номер ячейки), по которому производится запись (считывание).
Типичная структура адресной памяти, содержит запоминающий массив из N-разрядных ячеек и его аппаратное обрамление, включающее в себя регистр адреса РгА , имеющий k (k » log N) разрядов, информационный регистр РгИ , блок адресной выборки БАВ , блок усилителей считывания БУС , блок разрядных усилителей-формирователей сигналов записи БУЗ и блок управления памятью БУП .
По коду адреса в РгА БАВ формирует в соответствующей ячейке памяти сигналы, позволяющие произвести в ячейке считывание или запись слова.
Цикл обращения к памяти инициируется поступлением в БУП извне сигнала Обращение . Общая часть цикла обращения включает в себя прием в РгА с шины адреса ША адреса обращения и прием в БУП и расшифровку управляющего сигнала Операция , указывающего вид запрашиваемой операции (считывание или запись).
Далее при считывании БАВ дешифрирует адрес, посылает сигналы считывания в заданную адресом ячейку ЗМ, при этом код записанного в ячейке слова считывается усилителями считывания БУС и передается в РгИ . Операция считывания завершается выдачей слова из РгИ на выходную информационную шину ШИВых .
При записи помимо выполнения указанной выше общей части цикла обращения производится прием записываемого слова с входной информационной шины ШИВх и РгИ . Затем в выбранную БАВ ячейку записывается слово из РгИ .
Блок управления БУП генерирует необходимые последовательности управляющих сигналов, инициирующих работу отдельных узлов памяти.
Ассоциативная память. В памяти этого типа поиск нужной информации производится не по адресу, а по ее содержанию (по ассоциативному признаку). При этом поиск по ассоциативному признаку (или последовательно по отдельным разрядам этого признака) происходит параллельно во времени для всех ячеек запоминающего массива. Во многих случаях ассоциативный поиск позволяет существенно упростить и ускорить обработку данных. Это достигается за счет того, что в памяти этого типа операция считывания информации совмещена с выполнением ряда логических операций.
Типичная структура ассоциативной памяти представлена на рис. 4.3. Запоминающий массив содержит N (n+1)-разрядных ячеек. Для указания занятости ячейки используется служебный n-й разряд (0 - ячейка свободна, 1 - в ячейке записано слово).
Обычно в запоминающих устройствах доступ к информации требует указания адреса ячейки. Однако значительно удобнее искать информацию не по адресу, а опираясь на какой-нибудь характерный признак, содержащийся в самой информации. Такой принцип лежит в основе ЗУ, известного как ассоциативное запоминающее устройство (АЗУ). В литературе встречаются и иные названия подобного ЗУ: память, адресуемая по содержанию (content addressable memory); память, адресуемая по данным (data addressable memory); память с параллельным поиском (parallel search memory); каталоговая память (catalog memory); информационное ЗУ (information storage); тегированная память (tag memory).
Ассоциативное ЗУ – это устройство, способное хранить информацию, сравнивать ее с некоторым заданным образцом и указывать на их соответствие или несоответствие друг другу.
В отличие от обычной машинной памяти (памяти произвольного доступа или RAM), в которой пользователь задает адрес памяти и ОЗУ возвращает слово данных, хранящееся по этому адресу, АП разработана таким образом, чтобы пользователь задавал слово данных, и АП ищет его во всей памяти, чтобы выяснить, хранится ли оно где-нибудь в нем. Если слово данных найдено, АП возвращает список одного или более адресов хранения, где слово было найдено (и в некоторых архитектурах, также возвращает само слово данных, или другие связанные части данных). Таким образом, АП - аппаратная реализация того, что в терминах программирования назвали бы ассоциативным массивом.
Ассоциативный признак– признак, по которому производится поиск информации.
Признак поиска– кодовая комбинация, выступающая в роли образца для поиска.
Ассоциативный признак может быть частью искомой информации или дополнительно придаваться ей. В последнем случае его принято называть тегом или ярлыком.
Структура ассоциативного ЗУ
АЗУ включает в себя:
- запоминающий массив для хранения N m-разрядных слов, в каждом из которых несколько младших разрядов занимает служебная информация;
- регистр ассоциативного признака, куда помещается код искомой информации (признак поиска). Разрядность регистра k обычно меньше длины слова т ;
- схемы совпадения, используемые для параллельного сравнения каждого бита всех хранимых слов с соответствующим битом признака поиска и выработки сигналов совпадения;
- регистр совпадений, где каждой ячейке запоминающего массива соответствует один разряд, в который заносится единица, если все разряды соответствующей ячейки совпали с одноименными разрядами признака поиска;
- регистр маски, позволяющий запретить сравнение определенных битов;
- комбинационную схему, которая на основании анализа содержимого регистра совпадений формирует сигналы, характеризующие результаты поиска информации.
При обращении к АЗУ сначала в регистре маски обнуляются разряды, которые не должны учитываться при поиске информации. Все разряды регистра совпадений устанавливаются в единичное состояние. После этого в регистр ассоциативного признака заносится код искомой информации (признак поиска) и начинается ее поиск, в процессе которого схемы совпадения одновременно сравнивают первый бит всех ячеек запоминающего массива с первым битом признака поиска. Те схемы, которые зафиксировали несовпадение, формируют сигнал, переводящий соответствующий бит регистра совпадений в нулевое состояние. Так же происходит процесс поиска и для остальных незамаскированных битов признака поиска. В итоге единицы сохраняются лишь в тех разрядах регистра совпадений, которые соответствуют ячейкам, где находится искомая информация. Конфигурация единиц в регистре совпадений используется в качестве адресов, по которым производится считывание из запоминающего массива. Из-за того что результаты поиска могут оказаться неоднозначными, содержимое регистра совпадений подается на комбинационную схему, где формируются сигналы, извещающие о том, что искомая информация:
- а0 – не найдена;
- а1 – содержится в одной ячейке;
- а2 – содержится более чем в одной ячейке.
Формирование содержимого регистра совпадений и сигналов a0, a1, а2 носит название операции контроля ассоциации. Она является составной частью операций считывания и записи, хотя может иметь и самостоятельное значение.
При считывании сначала производится контроль ассоциации по аргументу поиска. Затем, при а0=1 считывание отменяется из-за отсутствия искомой информации, приa1=1 считывается слово, на которое указывает единица в регистре совпадений, а при а2=1 сбрасывается самая старшая единица в регистре совпадений и извлекается соответствующее ей слово. Повторяя эту операцию, можно последовательно считать все слова.
Запись в АП производится без указания конкретного адреса, в первую свободную ячейку. Для отыскания свободной ячейки выполняется операция считывания, в которой не замаскированы только служебные разряды, показывающие, как давно производилось обращение к данной ячейке, и свободной считается либо пустая ячейка, либо та, которая дольше всего не использовалась.
Главное преимущество ассоциативных ЗУ определяется тем, что время поиска информации зависит только от числа разрядов в признаке поиска и скорости опроса разрядов и не зависит от числа ячеек в запоминающем массиве.
Общность идеи ассоциативного поиска информации отнюдь не исключает разнообразия архитектур АЗУ. Конкретная архитектура определяется сочетанием четырех факторов:
- вида поиска информации;
- техники сравнения признаков;
- способа считывания информации при множественных совпадениях;
- способа записи информации.
В каждом конкретном применении АЗУ задача поиска информации может формулироваться по-разному.
Виды поиска информации :
- Простой (требуется полное совпадение всех разрядов признака поиска с одноименными разрядами слов, хранящихся в запоминающем массиве).
- Сложный:
- Поиск всех слов, больших или меньших заданного. Поиск слов в заданных пределах.
- Поиск максимума или минимума. Многократное выборка из АЗУ слова с максимальным или минимальным значением ассоциативного признака (с исключением его из дальнейшего поиска), по существу, представляет собой упорядоченную выборку информации. Упорядоченную выборку можно обеспечить и другим способом, если вести поиск слов, ассоциативный признак которых по отношению к признаку опроса является ближайшим большим или меньшим значением.
Очевидно, что реализация сложных методов поиска связана с соответствующими изменениями в архитектуре АЗУ, в частности с усложнением схемы ЗУ и введением в нее дополнительной логики.
Техника сравнения признаков:
При построении АЗУ выбирают из четырех вариантов организации опроса содержимого памяти. Варианты эти могут комбинироваться параллельно по группе разрядов и последовательно по группам. В плане времени поиска наиболее эффективным можно считать параллельный опрос как по словам, так и по разрядам, но не все виды запоминающих элементов допускают такую возможность.
Способ считывания информации при множественных совпадениях:
- С цепью очередности (с помощью достаточно сложного устройства, где фиксируются слова, образующие многозначный ответ. Цепь очередности позволяет производить считывание слов в порядке возрастания номера ячейки АЗУ независимо от величины ассоциативных признаков).
- Алгоритмически (в результате серии опросов).
Способ записи информации:
- По адресу.
- C сортировкой информации на входе АЗУ по величине ассоциативного признака (местоположение ячейки, куда будет помещено новое слово, зависит от соотношения ассоциативных признаков вновь записываемого слова и уже хранящихся в АЗУ слов).
- По совпадению признаков.
- С цепью очередности.
Из-за относительно высокой стоимости АЗУ редко используется как самостоятельный вид памяти.
В ассоциативной памяти элементы выбираются не по адресу, а по содержимому. Поясним последнее понятие более подробно. Для памяти с адресной организацией было введено понятие минимальной адресуемой единицы (МАЕ) как порции данных, имеющей индивидуальный адрес. Введем аналогичное понятие для ассоциативной памяти , и будем эту минимальную единицу хранения в ассоциативной памяти называть строкой ассоциативной памяти (СтрАП). Каждая СтрАП содержит два поля: поле тега (англ. tag - ярлык, этикетка, признак) и поле данных. Запрос на чтение к ассоциативной памяти словами можно выразить следующим образом: выбрать строку (строки), у которой (у которых) тег равен заданному значению.
Особо отметим, что при таком запросе возможен один из трех результатов:
- имеется в точности одна строка с заданным тегом;
- имеется несколько строк с заданным тегом;
- нет ни одной строки с заданным тегом.
Поиск записи по признаку - это действие, типичное для обращений к базам данных, и поиск в базе зачастую чвляется ассоциативным поиском. Для выполнения такого поиска следует просмотреть все записи и сравнить заданный тег с тегом каждой записи. Это можно сделать и при использовании для хранения записей обычной адресуемой памяти (и понятно, что это потребует достаточно много времени - пропорционально количеству хранимых записей!). Об ассоциативной памяти говорят тогда, когда ассоциативная выборка данных из памяти поддержана аппаратно. При записи в ассоциативную память элемент данных помещается в СтрАП вместе с присущим этому элементу тегом. Для этого можно использовать любую свободную СтрАП. Рассмотрим разновидности структурной организации КЭШ-памяти или способы отображения оперативной памяти на КЭШ .
Полностью ассоциативный КЭШ
Схема полностью ассоциативного КЭШа представлена на рисунке (см. рисунок ниже).
Опишем алгоритм работы системы с КЭШ-памятью. В начале работы КЭШ-память пуста. При выполнении первой же команды во время выборки ее код, а также еще несколько соседних байтов программного кода, - будут перенесены (медленно) в одну из строк КЭШа, и одновременно старшая часть адреса будет записана в соответствующий тег. Так происходит заполнение КЭШ-строки.
Если следующие выборки возможны из этого участка, они будут сделаны уже из КЭШа (быстро) - "КЭШ-попадание". Если же окажется, что нужного элемента в КЭШе нет, - "КЭШ-промахом". В этом случае обращение происходит к ОЗУ (медленно), и при этом одновременно заполняется очередная КЭШ-строка.
Схема полностью ассоциативной КЭШ-памяти
Обращение к КЭШу происходит следующим образом. После формирования исполнительного адреса его старшие биты, образующие тег, аппаратно (быстро) и одновременно сравниваются с тегами всех КЭШ-строк. При этом возможны только две ситуации из трех, перечисленных ранее: либо все сравнения дадут отрицательный результат (КЭШ-промах), либо положительный результат сравнения будет зафиксирован в точности для одной строки (КЭШ-попадание).
При считывании, если зафиксировано КЭШ-попадание, младшие разряды адреса определяют позицию в КЭШ-строке, начиная с которой следует выбирать байты, а тип операции определяет количество байтов. Очевидно, что если длина элемента данных превышает один байт, то возможны ситуации, когда этот элемент (частями) расположен в двух (или более) разных КЭШ-строках, тогда время на выборку такого элемента увеличится. Противодействовать этому можно, выравнивая операнды и команды по границам КЭШ-строк, что и учитывают при разработке оптимизирующих трансляторов или при ручной оптимизации кода.
Если произошел КЭШ-промах, а в КЭШе нет свободных строк, необходимо заменить одну строку КЭШа на другую строку.
Основная цель стратегии замещения - удерживать в КЭШ-памяти строки, к которым наиболее вероятны обращения в ближайшем будущем, и заменять строки, доступ к которым произойдет в более отдаленном времени или вообще не случится. Очевидно, что оптимальным будет алгоритм, который замещает ту строку, обращение к которой в будущем произойдет позже, чем к любой другой строке-КЭШ.
К сожалению, такое предсказание практически нереализуемо, и приходится привлекать алгоритмы, уступающие оптимальному. Вне зависимости от используемого алгоритма замещения, для достижения высокой скорости он должен быть реализован аппаратными средствами.
Среди множества возможных алгоритмов замещения наиболее распространенными являются четыре, рассматриваемые в порядке уменьшения их относительной эффективности. Любой из них может быть применен в полностью ассоциативном КЭШ.
Наиболее эффективным является алгоритм замещения на основе наиболее давнего использования (LRU - Least Recently Used ), при котором замещается та строка КЭШ-памяти, к которой дольше всего не было обращения. Проводившиеся исследования показали, что алгоритм LRU, который "смотрит" назад, работает достаточно хорошо в сравнении с оптимальным алгоритмом, "смотрящим" вперед.
Наиболее известны два способа аппаратурной реализации этого алгоритма. В первом из них с каждой строкой КЭШ-памяти ассоциируют счетчик. К содержимому всех счетчиков через определенные интервалы времени добавляется единица. При обращении к строке ее счетчик обнуляется. Таким образом, наибольшее число будет в счетчике той строки, к которой дольше всего не было обращений и эта строка - первый кандидат на замещение.
Второй способ реализуется с помощью очереди, куда в порядке заполнения строк КЭШ-памяти заносятся ссылки на эти строки. При каждом обращении к строке ссылка на нее перемещается в конец очереди. В итоге первой в очереди каждый раз оказывается ссылка на строку, к которой дольше всего не было обращений. Именно эта строка прежде всего и заменяется.
Другой возможный алгоритм замещения - алгоритм, работающий по принципу "первый вошел, первый вышел" (FIFO - First In First Out ). Здесь заменяется строка, дольше всего находившаяся в КЭШ-памяти. Алгоритм легко реализуется с помощью рассмотренной ранее очереди, с той лишь разницей, что после обращения к строке положение соответствующей ссылки в очереди не меняется.
Еще один алгоритм - замена наименее часто использовавшейся строки (LFU - Least Frequently Used). Заменяется та строка в КЭШ-памяти, к которой было меньше всего обращений. Принцип можно воплотить на практике, связав каждую строку со счетчиком обращений, к содержимому которого после каждого обращения добавляется единица. Главным претендентом на замещение является строка, счетчик которой содержит наименьшее число.
Простейший алгоритм - произвольный выбор строки для замены. Замещаемая строка выбирается случайным образом. Реализовано это может быть, например, с помощью счетчика, содержимое которого увеличивается на единицу с каждым тактовым импульсом, вне зависимости от того, имело место попадание или промах. Значение в счетчике определяет заменяемую строку.
Кроме тега и байтов данных в КЭШ-строке могут содержаться дополнительные служебные поля, среди которых в первую очередь следует отметить бит достоверности V (от valid - действительный имеющий силу) и бит модификации M (от modify - изменять, модифицировать). При заполнении очередной КЭШ-строки V устанавливается в состояние "достоверно", а M - в состояние "не модифицировано". В случае, если в ходе выполнения программы содержимое данной строки было изменено, переключается бит M, сигнализируя о том, что при замене данной строки ее содержимое следует переписать в ОЗУ. Если по каким-либо причинам произошло изменение копии элемента данной строки, хранимого в другом месте (например в ОЗУ), переключается бит V. При обращении к такой строке будет зафиксирован КЭШ-промах (несмотря на то, что тег совпадает), и обращение произойдет к основному ОЗУ. Кроме того, служебное поле может содержать биты, поддерживающие алгоритм LRU.
Оценка объема оборудования
Типовой объем КЭШ-памяти в современной системе - 8…1024 кбайт, а длина КЭШ-строки 4…32 байт. Дальнейшая оценка делается для значений объема КЭШа 256 кбайт и длины строки 32 байт, что характерно для систем с процессорами Pentium и PentiumPro. Длина тега при этом равна 27 бит, а количество строк в КЭШе составит 256К/ 32=8192. Именно столько цифровых компараторов 27 битных кодов потребуется для реализации вышеописанной структуры.
Приблизительная оценка затрат оборудования для построения цифрового компаратора дает значение 10 транз/бит, а общее количество транзисторов только в блоке компараторов будет равно:
10*27*8192 = 2 211 840,
что приблизительно в полтора раза меньше общего количества транзисторов на кристалле Pentium. Таким образом, ясно, что описанная структура полностью ассоциативной КЭШ-памяти () реализуема только при малом количестве строк в КЭШе, т.е. при малом объеме КЭШа (практически не более 32…64 строк). КЭШ большего объема строят по другой структуре.
Материал из Википедии - свободной энциклопедии
Ассоциативная память (АП) или (АЗУ) является особым видом машинной памяти, используемой в приложениях очень быстрого поиска. Известна также как память, адресуемая по содержимому , ассоциативное запоминающее устройство , контентно-адресуемая память или ассоциативный массив , хотя последний термин чаще используется в программировании для обозначения структуры данных. (Hannum и др., 2004)
Аппаратный ассоциативный массив
В отличие от обычной машинной памяти (памяти произвольного доступа, или RAM), в которой пользователь задает адрес памяти и ОЗУ возвращает слово данных, хранящееся по этому адресу, АП разработана таким образом, чтобы пользователь задавал слово данных, и АП ищет его во всей памяти, чтобы выяснить, хранится ли оно где-нибудь в нем. Если слово данных найдено, АП возвращает список одного или более адресов хранения, где слово было найдено (и в некоторых архитектурах, также возвращает само слово данных, или другие связанные части данных). Таким образом, АП - аппаратная реализация того, что в терминах программирования назвали бы ассоциативным массивом.
Промышленные стандарты адресуемой содержанием памяти
Определение основного интерфейса для АП и других Сетевых Элементов Поиска (Network Search Elements, NSE) было специфицировано в Соглашении о возможности взаимодействий (Interoperability Agreement), названном Интерфейс предысторий (Look-Aside Interface) (LA-1 и LA-1B ), который был разработан Форумом Сетевой Обработки, который позже был объединен с Оптическим Межсетевым Форумом (Optical Internetworking Forum, OIF). Многочисленные устройства были произведены компаниями Integrated Device Technology, Cypress Semiconductor, IBM, Netlogic Micro Systems и другими по этим соглашениям LA. 11 декабря 2007, OIF издал соглашение об интерфейсе последовательной предыстории (Serial Lookaside, SLA ).
Реализация на полупроводниках
Из-за того, что АП разработана, чтобы искать во всей памяти одной операцией, это получается намного быстрее, чем поиск в RAM фактически во всех приложениях поиска. Однако, есть и минус в большей стоимости АП. В отличие от чипа RAM, у которого хранилища простые, у каждого отдельного бита памяти в полностью параллельной АП должна быть собственная присоединенная схема сравнения, чтобы обнаружить совпадение между сохраненным битом и входным битом. К тому же, выходы сравнений от каждой ячейки в слове данных должны быть объединены, чтобы привести к полному результату сравнения слова данных. Дополнительная схема увеличивает физический размер чипа АП, что увеличивает стоимость производства. Дополнительная схема также увеличивает рассеиваемую мощность, так как все схемы сравнений активны на каждом такте. Как следствие, АП используется только в специализированных приложениях, где скорость поиска не может быть достигнута, используя другие, менее дорогостоящие, методы.
Альтернативные реализации
Для того, чтобы достигнуть другого баланса между скоростью, размером памяти и стоимостью, некоторые реализации эмулируют функции АП путём использования стандартного поиска по дереву или алгоритмов хеширования, реализованных аппаратно, также используя для ускорения эффективной работы такие аппаратные трюки, как репликация и конвейерная обработка. Эти проекты часто используются в маршрутизаторах.
Троичная ассоциативная память
Двоичная АП - простейший тип ассоциативной памяти, который использует слова поиска данных, состоявшие полностью из единиц и нулей. В троичной АП (Ternary Content Addressable Memory, TCAM ) добавляется третье значение для сравнения «X» или «не важно», для одного или более битов в сохраненном слове данных, добавляя дополнительную гибкость поиску.
Например, в троичной АП могло бы быть сохранено слово «10XX0», которое выдаст совпадение на любое из четырех слов поиска «10000», «10010», «10100», или «10110». Добавление гибкости к поиску приходит за счет увеличения сложности памяти, поскольку внутренние ячейки теперь должны кодировать три возможных состояния вместо двух. Это дополнительное состояние обычно осуществляется добавлением бита маски «важности» («важно»/«не важно») к каждой ячейке памяти.
Голографическая ассоциативная память обеспечивает математическую модель для интегрированного ассоциативного воспоминания бита «не важно», используя комплекснозначное представление. [ ] предположительно www.mit.edu/~9.54/fall14/Classes/class07/Plate.pdf and www.mit.edu/~9.54/fall14/Classes/class07/Plate.pdf
Примеры приложений
Адресуемая содержанием память часто используется в компьютерных сетевых устройствах. Например, когда сетевой коммутатор (switch) получает фрейм данных на один из его портов, это обновляет внутреннюю таблицу с источником MAC-адреса фрейма и порта, на который он был получен. Потом он ищет MAC-адрес назначения в таблице, чтобы определить, на какой порт фрейм должен быть отправлен, и отсылает его на этот порт. Таблица MAC- адресов обычно реализована на двоичной АП, таким образом порт назначения может быть найден очень быстро, уменьшая время ожидания коммутатора.
Троичные АП часто используются в тех сетевых маршрутизаторах, в которых у каждого адреса есть две части: (1) адрес сети, который может измениться в размере в зависимости от конфигурации подсети, и (2) адрес хоста, который занимает оставшиеся биты. У каждой подсети есть маска сети, которая определяет, какие биты - адрес сети и какие биты - адрес хоста. Маршрутизация делается путём сверки с таблицей маршрутизации, которую поддерживает маршрутизатор (router). В ней содержатся все известные адреса сети назначения, связанная с ними маска сети и информация, необходимая пакетам, маршрутизируемым по этому назначению. Маршрутизатор, реализованный без АП, сравнивает адрес назначения пакета, который будет разбит, с каждым входом в таблице маршрутизации, выполняя при этом логическое И с маской сети и сравнивая результаты с адресом сети. Если они равны, соответствующая информация направления используется, чтобы отправить пакет. Использование троичной АП для таблицы маршрутизации делает процесс поиска очень эффективным. Адреса хранятся с использованием бита «не важно» в части адреса хоста, таким образом поиск адреса назначения в АП немедленно извлекает правильный вход в таблице маршрутизации; обе операции - применения маски и сравнения - выполняются аппаратно средствами АП.
Другие приложения АП включают
- Диспетчеры кэша центрального процессора и ассоциативные буфера трансляции (TLB)
Библиография
- Кохонен Т. Ассоциативные запоминающие устройства. М.: Мир, 1982. - 384 с.
На английском языке
- Anargyros Krikelis, Charles C. Weems (editors) (1997) Associative Processing and Processors , IEEE Computer Science Press. ISBN 0-8186-7661-2
- Pagiamtis, K. & Sheikholeslami, A. (2006, March). IEEE J. of Solid-State Circuits , 41(3), 712–727.
- . U.S. Patent 6,823,434.
Напишите отзыв о статье "Ассоциативная память"
Примечания
Ссылки
- Ассоциативное запоминающее устройство - статья из Большой советской энциклопедии .
На английском:
См. также
- Процессор в памяти , Processor-in-memory (PIM), или Вычисляющее ОЗУ или Computational RAM, C-RAM, также, «Вычисления в памяти»
- Вычисления с памятью , концепция и реализация в виде разновидности ПЛИС
Отрывок, характеризующий Ассоциативная память
– У графини просите, а я не распоряжаюсь.– Ежели затруднительно, пожалуйста, не надо, – сказал Берг. – Мне для Верушки только очень бы хотелось.
– Ах, убирайтесь вы все к черту, к черту, к черту и к черту!.. – закричал старый граф. – Голова кругом идет. – И он вышел из комнаты.
Графиня заплакала.
– Да, да, маменька, очень тяжелые времена! – сказал Берг.
Наташа вышла вместе с отцом и, как будто с трудом соображая что то, сначала пошла за ним, а потом побежала вниз.
На крыльце стоял Петя, занимавшийся вооружением людей, которые ехали из Москвы. На дворе все так же стояли заложенные подводы. Две из них были развязаны, и на одну из них влезал офицер, поддерживаемый денщиком.
– Ты знаешь за что? – спросил Петя Наташу (Наташа поняла, что Петя разумел: за что поссорились отец с матерью). Она не отвечала.
– За то, что папенька хотел отдать все подводы под ранепых, – сказал Петя. – Мне Васильич сказал. По моему…
– По моему, – вдруг закричала почти Наташа, обращая свое озлобленное лицо к Пете, – по моему, это такая гадость, такая мерзость, такая… я не знаю! Разве мы немцы какие нибудь?.. – Горло ее задрожало от судорожных рыданий, и она, боясь ослабеть и выпустить даром заряд своей злобы, повернулась и стремительно бросилась по лестнице. Берг сидел подле графини и родственно почтительно утешал ее. Граф с трубкой в руках ходил по комнате, когда Наташа, с изуродованным злобой лицом, как буря ворвалась в комнату и быстрыми шагами подошла к матери.
– Это гадость! Это мерзость! – закричала она. – Это не может быть, чтобы вы приказали.
Берг и графиня недоумевающе и испуганно смотрели на нее. Граф остановился у окна, прислушиваясь.
– Маменька, это нельзя; посмотрите, что на дворе! – закричала она. – Они остаются!..
– Что с тобой? Кто они? Что тебе надо?
– Раненые, вот кто! Это нельзя, маменька; это ни на что не похоже… Нет, маменька, голубушка, это не то, простите, пожалуйста, голубушка… Маменька, ну что нам то, что мы увезем, вы посмотрите только, что на дворе… Маменька!.. Это не может быть!..
Граф стоял у окна и, не поворачивая лица, слушал слова Наташи. Вдруг он засопел носом и приблизил свое лицо к окну.
Графиня взглянула на дочь, увидала ее пристыженное за мать лицо, увидала ее волнение, поняла, отчего муж теперь не оглядывался на нее, и с растерянным видом оглянулась вокруг себя.
– Ах, да делайте, как хотите! Разве я мешаю кому нибудь! – сказала она, еще не вдруг сдаваясь.
– Маменька, голубушка, простите меня!
Но графиня оттолкнула дочь и подошла к графу.
– Mon cher, ты распорядись, как надо… Я ведь не знаю этого, – сказала она, виновато опуская глаза.
– Яйца… яйца курицу учат… – сквозь счастливые слезы проговорил граф и обнял жену, которая рада была скрыть на его груди свое пристыженное лицо.
– Папенька, маменька! Можно распорядиться? Можно?.. – спрашивала Наташа. – Мы все таки возьмем все самое нужное… – говорила Наташа.
Граф утвердительно кивнул ей головой, и Наташа тем быстрым бегом, которым она бегивала в горелки, побежала по зале в переднюю и по лестнице на двор.
Люди собрались около Наташи и до тех пор не могли поверить тому странному приказанию, которое она передавала, пока сам граф именем своей жены не подтвердил приказания о том, чтобы отдавать все подводы под раненых, а сундуки сносить в кладовые. Поняв приказание, люди с радостью и хлопотливостью принялись за новое дело. Прислуге теперь это не только не казалось странным, но, напротив, казалось, что это не могло быть иначе, точно так же, как за четверть часа перед этим никому не только не казалось странным, что оставляют раненых, а берут вещи, но казалось, что не могло быть иначе.
Все домашние, как бы выплачивая за то, что они раньше не взялись за это, принялись с хлопотливостью за новое дело размещения раненых. Раненые повыползли из своих комнат и с радостными бледными лицами окружили подводы. В соседних домах тоже разнесся слух, что есть подводы, и на двор к Ростовым стали приходить раненые из других домов. Многие из раненых просили не снимать вещей и только посадить их сверху. Но раз начавшееся дело свалки вещей уже не могло остановиться. Было все равно, оставлять все или половину. На дворе лежали неубранные сундуки с посудой, с бронзой, с картинами, зеркалами, которые так старательно укладывали в прошлую ночь, и всё искали и находили возможность сложить то и то и отдать еще и еще подводы.
– Четверых еще можно взять, – говорил управляющий, – я свою повозку отдаю, а то куда же их?
– Да отдайте мою гардеробную, – говорила графиня. – Дуняша со мной сядет в карету.
Отдали еще и гардеробную повозку и отправили ее за ранеными через два дома. Все домашние и прислуга были весело оживлены. Наташа находилась в восторженно счастливом оживлении, которого она давно не испытывала.
– Куда же его привязать? – говорили люди, прилаживая сундук к узкой запятке кареты, – надо хоть одну подводу оставить.
– Да с чем он? – спрашивала Наташа.
– С книгами графскими.
– Оставьте. Васильич уберет. Это не нужно.
В бричке все было полно людей; сомневались о том, куда сядет Петр Ильич.
– Он на козлы. Ведь ты на козлы, Петя? – кричала Наташа.
Соня не переставая хлопотала тоже; но цель хлопот ее была противоположна цели Наташи. Она убирала те вещи, которые должны были остаться; записывала их, по желанию графини, и старалась захватить с собой как можно больше.
Во втором часу заложенные и уложенные четыре экипажа Ростовых стояли у подъезда. Подводы с ранеными одна за другой съезжали со двора.
Коляска, в которой везли князя Андрея, проезжая мимо крыльца, обратила на себя внимание Сони, устраивавшей вместе с девушкой сиденья для графини в ее огромной высокой карете, стоявшей у подъезда.
– Это чья же коляска? – спросила Соня, высунувшись в окно кареты.
– А вы разве не знали, барышня? – отвечала горничная. – Князь раненый: он у нас ночевал и тоже с нами едут.
– Да кто это? Как фамилия?
– Самый наш жених бывший, князь Болконский! – вздыхая, отвечала горничная. – Говорят, при смерти.
Соня выскочила из кареты и побежала к графине. Графиня, уже одетая по дорожному, в шали и шляпе, усталая, ходила по гостиной, ожидая домашних, с тем чтобы посидеть с закрытыми дверями и помолиться перед отъездом. Наташи не было в комнате.
– Maman, – сказала Соня, – князь Андрей здесь, раненый, при смерти. Он едет с нами.
Графиня испуганно открыла глаза и, схватив за руку Соню, оглянулась.
– Наташа? – проговорила она.
И для Сони и для графини известие это имело в первую минуту только одно значение. Они знали свою Наташу, и ужас о том, что будет с нею при этом известии, заглушал для них всякое сочувствие к человеку, которого они обе любили.
– Наташа не знает еще; но он едет с нами, – сказала Соня.
– Ты говоришь, при смерти?
Соня кивнула головой.
Графиня обняла Соню и заплакала.
«Пути господни неисповедимы!» – думала она, чувствуя, что во всем, что делалось теперь, начинала выступать скрывавшаяся прежде от взгляда людей всемогущая рука.
– Ну, мама, все готово. О чем вы?.. – спросила с оживленным лицом Наташа, вбегая в комнату.
– Ни о чем, – сказала графиня. – Готово, так поедем. – И графиня нагнулась к своему ридикюлю, чтобы скрыть расстроенное лицо. Соня обняла Наташу и поцеловала ее.
Наташа вопросительно взглянула на нее.
– Что ты? Что такое случилось?
– Ничего… Нет…
– Очень дурное для меня?.. Что такое? – спрашивала чуткая Наташа.
Этот цикл статей описывает волновую модель мозга, серьезно отличающуюся от традиционных моделей. Настоятельно рекомендую тем, кто только присоединился, начинать чтение с .
В предыдущей части мы показали как может выглядеть распределенная память. Основная идея заключается в том, что общий волновой идентификатор может объединить нейроны, которые своей активностью формируют запоминаемую картину. Чтобы воспроизвести конкретное событие достаточно запустить по коре соответствующий идентификатор воспоминания. Его распространение восстановит ту же картину активности, что была на коре на момент фиксации этого воспоминания. Но главный вопрос - это как нам получить требуемый идентификатор? Ассоциативность памяти подразумевает, что по набору признаков мы можем отобрать события, в описании которых присутствовали эти признаки. То есть должен существовать нейронный механизм, который позволит по описанию в определенных признаках, получить идентификатор подходящего под эти признаки воспоминания.
Когда мы говорили о распространении нейронных волн, мы исходили из того, что нейрон хранит на внесинаптической мембране те волновые картины, участником которых он является. Встретив знакомую картину, нейрон своим спайком создает продолжение уникального узора. И тут важно, что нейрон не просто в состоянии узнать волновую картину, а то, что он сам – часть распространяющегося узора. Только будучи сам частью уникальной волны нейрон способен участвовать в ее распространении.
Чтобы не запутаться в последующих рассуждениях, еще раз повторим основные свойства волновой модели коры. Если отметить нейроны, относящиеся к одному волновому узору или – другими словами – идентификатору, то получится что-то вроде набора точек, изображенного на рисунке ниже.

Взяв любое место коры и активировав элементы идентификатора, мы получим волну, распространяющуюся от активного места, повторяющую характерный для идентификатора узор (рисунок ниже).

Проходя через каждое место коры, волна будет «высвечивать» фрагмент своего уникального узора. Так, стартовав из области 1, волна, дойдя до области 2, создаст там свой предопределенный идентификатором уникальный узор (рисунок ниже).

По уникальности узора можно в каждом месте коры определить, какие идентификаторы составляют волну.
Если мы на спокойной коре в области 2 воспроизведем уже знакомый нам узор, то он также создаст волну, которая, распространившись до области 1, создаст там все тот же паттерн, характерный именно для этого идентификатора.

Из всего этого следует, что для узнавания идентификатора достаточно в любом месте коры запомнить, какой узор именно в этом месте создает волна. Это можно запомнить либо на синапсах нейрона, либо на внесинаптической части мембраны. Запоминание на синапсах приводит к вызванной активности (пакету импульсов) при узнавании, запоминание на метаботропных рецептивных кластерах позволяет получать единичные спайки при появлении знакомой волны.
Сложнее, если нам надо воспроизвести идентификатор. Для этого нам надо активировать хотя бы единичными спайками группу близко расположенных нейронов, относящихся к требуемому идентификатору. Описывая обратную проекцию и вводя несколько медиаторов, мы как раз показывали механизм, реализующий нечто подобное.
Говоря об ассоциативности понятий, мы показали, что запрос, построенный на волнах идентификаторов, возвращает набор идентификаторов понятий, ассоциативно связанных с понятиями, содержащимися в запросе.
Чтобы показать механизм извлечения воспоминаний из ассоциативной событийной памяти нам надо показать, как волновой запрос, состоящий из понятий-признаков, может выдать уникальные гиппокамповские идентификаторы воспоминаний, подходящих под этот запрос. Если мы сможем получить такой набор идентификаторов и отобрать из них один, то, запустив этот идентификатор обратно по коре, мы получим активность нейронов-детекторов, содержащих этот идентификатор на внесинаптической мембране, а это будет равносильно восстановлению всей описательной картины требуемого воспоминания.
Напомню, про нашу упрощенность и схематичность описания. Далее я изложу возможный нейронный механизм ассоциативной памяти, не утверждая при этом, что мозг работает именно так.
Опять ненадолго обратимся к строению реальных нейронов. Тело нейрона – сома – имеет ограниченную площадь и не может обеспечить места для всех синаптических контактов. Большая часть синапсов приходится на разветвленную структуру, называемую дендритом или дендритным деревом (рисунок ниже). Количество синапсов, располагающихся на дендрите, в 10-20 раз превышает количество синапсов на соме.

Формы дендритных деревьев (Greg Stuart, Nelson Spruston, Michael Häusser)
Было обнаружено, что нейрон ведет себя по-разному в зависимости от того, приходят ли сигналы на синапсы на одну или на разные дендритные ветки (Shepherd G.M., Brayton R.K., Miller J.P., Segev I., Rinzel J., Rall W., 1985). Одновременный приход импульсов на синапсы одной ветки вызывает значительно более сильный ответ нейрона, чем сигнал, распределенный по разным веткам.
На основе наблюдений такого рода родилась гипотеза о том, что дендритные ветки могут играть роль детекторов совпадений (Softky, 1994). Ее суть в том, что сигналам, рождающимся в удаленных ветках дендритного дерева, для генерации спайка нейрона необходимо, чтобы были активны сегменты дендритного дерева, лежащие по дороге сигнала к соме.
Такой эффект был показан для пирамидальных нейронов (Jarsky T., Alex Roxin A., Kath W.L., Spruston N., 2005), но можно полагать, что что-то подобное свойственно и нейронам других типов.

Фазы распространения сигнала в апикальных и наклонных сегментах пирамидального нейрона гиппокампа. Сигнал возникает в апикальном пучке (красная точка) и распространяется до коллатерали Шаффера (зеленая точка). Сигнал в более близком к соме месте дендрита не позволяет далекому сигналу угаснуть и способствует возникновению спайка (Jarsky T., Alex Roxin A., Kath W.L., Spruston N., 2005)
Распространение импульса по дендриту сопровождается его значительным затуханием. По идее, влияние удаленных (дистальных) синапсов должно быть значительно меньше, чем влияние близких (проксимальных). Однако были показаны механизмы, выравнивающие вклад таких синапсов, что вылилось в концепцию «демократии синапсов» (Clifton C. Rumsey, L. F. Abbott, 2006). Выравнивание вклада синапсов вдоль ветки дендрита позволяет рассматривать ветки как самостоятельные логические элементы, сигналы которых каким-то образом далее обрабатываются нейроном. Это означает, что теоретически, меняя конфигурацию дендрита и реакцию сомы, можно получить нейроны с различными логическими свойствами.
Например, в популярной концепции «иерархической темпоральной памяти» Джеффа Хокинса применяются нейроны, использующие автономные элементы, работающие в режиме «или» (рисунок ниже).

Модель нейрона с набором дендритных логических автономных элементов в сопоставлении с пирамидальным нейроном (Хокинс, 2011)
Вполне уместно предположить, что и реальный мозг оперирует нейронами с существенным разнообразием свойств.
Теперь перейдем, собственно, к описанию ассоциативной событийной памяти. Предположим, что у нас есть нейроны двух типов, образующие плоскую кору. Рецептивные поля этих нейронов охватывают некую локальную область своего окружения, куда попадают нейроны обоих типов. Условно разнесем их на два слоя, помня при этом о перекрестном распределении связей.
Зададим нейроны первого типа такими, чтобы они распространяли волну информационного идентификатора. Нейроны же второго типа заставим распространять исключительно волны идентификаторов гиппокампа (рисунок ниже).

Распространение двух независимых волн на нейронах с разным типом медиатора
Для этого разведем их аксоны и внесинаптические рецепторы по используемым медиаторам (таблица ниже). Обратите внимание, что для задания волнового распространения синаптические рецепторы нам не важны.
| Синапсы | Вне синапсов | Аксон | |
|---|---|---|---|
| Тип 1 | A | A | |
| Тип 2 | B | B |
При таком задании медиаторов и рецепторов волны на двух слоях никак не будут влиять друг на друга.
Теперь усложним нейроны второго типа, сделаем их дендритные деревья состоящими из двух типов веток, отличающихся внесинаптическими медиаторами. При моделировании однородные ветки можно объединить и в результате оставить два дендритных сегмента, работающих по принципу «или» (таблица ниже).
| Сегмент | Синапсы | Вне синапсов | Аксон | |
|---|---|---|---|---|
| Тип 1 | A | A | ||
| Тип 2 | 1 | B | B | |
| 2 | A |
Предположим, что пока шло обучение нейронов тому, как распространять волны идентификаторов, у нейронов второго типа был заблокирован второй сегмент, чувствительный к «чужому» медиатору. Вся информация, необходимая для формирования волн, у нейронов второго типа будет откладываться на внесинаптической памяти первого сегмента.
Если теперь мы включим вторые сегменты, то на них начнется запоминание волновых картин, распространяющихся по нейронам первого типа. Будем полагать, что внесинаптическое запоминание происходит в момент, когда нейрон генерирует спайк. При этом фиксируется не моментальная картина активности на синапсах, а накопленная за весь такт распространения волны. Накопление позволит нам запомнить фрагмент волны первого уровня, даже если фазы волн двух уровней в месте запоминания не совпадают. То есть, когда нейрон второго уровня выдаст спайк, он зафиксирует картину информационной активности, даже если она была какое-то время назад.
Предположим, что мы провели один такт такого запоминания. Все нейроны второго уровня, распространяющие волну идентификатора гиппокампа, активные в этом такте, запомнят на своих вторых сегментах фрагменты информационной волны, прошедшей по нейронам первого типа. Это значит, что если мы когда-нибудь повторим такую же волну описания, то все нейроны второго уровня, которые узнают эту картину, дадут спайк. Общая картина этих спайков воспроизведет тот самый идентификатор гиппокампа, который был на момент запоминания этого информационного образа.
Так можно запоминать различные описательные картины. При повторении соответствующих описаний нейроны второго уровня будут выдавать суммарное сочетание всех идентификаторов гиппокампа, попадающих под текущее описание.
Видно, что такое запоминание крайне расточительно. Мы запоминаем каждый образ на всех активных нейронах второго типа. Хотя для воспроизведения идентификатора нам нужен всего лишь малый локальный участок, способный запустить волну. Чтобы исправить ситуацию, будем запоминать информационную волну не на всех активных нейронах второго типа, а только на тех, которые попадают в области с высокой вызванной активностью нейронов первого типа. То есть вспомним, что информация дуалистична. Она одновременно и идентификаторная волна, и активность паттернов вызванной активности. Волна даст нам узор для запоминания, а паттерны укажут места для этого.
Самый простой способ выбора места – это воспользоваться тем же полем активности, которое мы использовали для пространственной самоорганизации паттернов. В такой конфигурации запоминание можно представить так. В местах коры, где информационная картина создает паттерны вызванной активности, формируется поле активности. Все активные нейроны второго типа, распространяющие волну гиппокампа, для которых поле активности выше определенного порога, фиксируют на внесинаптической памяти картины, описываемые информационной волной.
Подав информационную волну-запрос, мы получим активность нейронов второго типа, узнавших этот запрос. Локальные группы таких нейронов будут излучать идентификаторы гиппокампа, относящиеся ко всем воспоминаниям, ассоциативно связанным с этим запросом.
Мы показали, как могут фиксироваться и восстанавливаться уникальные идентификаторы воспоминаний. Ранее мы показали, что если на нейронах-детекторах хранить память о таких уникальных идентификаторах, то можно восстанавливать образы, соответствующие запомненным моментам. В таблице ниже приведена возможная конфигурация медиаторов для такой памяти.
| Сегмент | Синапсы | Вне синапсов | Аксон | |
|---|---|---|---|---|
| Тип 1 | 1 | A | A | |
| 2 | B | |||
| Тип 2 | 1 | B | B | |
| 2 | A |
Задание области запоминания через поле активности – достаточно грубый инструмент. Есть вполне очевидные пути по совершенствованию конструкции. Например, можно через синаптическое обучение нейронов второго типа создать из них области, соответствующие понятиям, находящимся в этом месте коры. Используя концепцию дендритного детектора совпадений, можно сделать так, что активность понятия будет обязательным условием, как для записи, так и для обратной генерации идентификаторов воспоминаний, связанных с этим понятием.
Вообще же богатство инструментария, которое предоставляет волновая модель коры с многосекционными нейронами, позволяет реализовывать достаточно сложные и интересные конструкции. Ограничимся пока уже приведенными самыми простыми схемами, чтобы окончательно не запутать повествование.