Здравствуйте, уважаемые читатели блога сайт. Сегодня хочу поговорить о таком понятии, как резервное копировании файлов и баз данных вашего ресурса.
Да, конечно, многие хостеры () осуществляют бэкап в автоматическом режиме и, в случае чего, вы сможете обратиться к ним за помощью. Но как говорится: на хостера надейся, а сам не плошай.
Ситуаций, в которых вы можете потерять данные своего проекта , можно привести много, да и вы сами, наверное, об этом наслышаны. Не стоит полагаться на милость вашего хостера. Надо самому сделать backup и хранить его у себя на компьютере.
Так будет значительно надежнее и спокойнее. Если все-таки ваш интернет проект рухнул, а восстанавливать его не из чего, то попробуйте попытать счастье в Webarchive (здесь про более подробно написано), ибо он постоянно делает слепки подавляющего большинства сайтов в интернете.
Как сделать бэкап файлов сайта с помощью FileZilla
Как вы уже, наверное, знаете, сайты , созданные на основе какого-либо движка, будь то Joomla, WordPress или SMF, состоят из двух важных частей :
- Во-первых, это собственно сами файлы движка и установленных в нем расширений, картинки и...
- А во-вторых, это базы данных, где хранятся тексты ваших статей, постов и т.п.
В базе данных (БД) могут храниться также настройки некоторых параметров движка и его расширений. Я уже писал об этом в статье про . Такая организация имеет массу преимуществ.
Значит наша задача сводится к резервному копированию всего этого богатства. Причем, частота резервирования БД, обычно, определяется частотой появления новой информации на вашем проекте. Оптимальным, на мой взгляд, является копирование базы ежедневно. Благо весят они, как правило, не очень много и такой бэкап осуществляется очень быстро. Обновлять же резервные копии файлов вашего проекта следует, пожалуй, только после того, как вы внесли какие-то изменения в них: установили какие-либо расширения, обновили версию движка и т.п.
Начнем, пожалуй, с нашего первого помощника под названием FileZilla , хотя вместо нее вы можете использовать любой другой FTP-менеджер, вплоть до , но я предпочитаю именно это детище свободного ПО. мною уже были довольно подробно описаны в приведенной статье, посему останавливаться на этом подробно не будем (хотите — сами почитайте, особливо про хранение в этой программе паролей и проблемы с этим связанные).
Давайте рассмотрим, как сделать бэкап файлов с ее помощью. Получив доступ к серверу своего хостинга, вы должны зайти в корневую папку (она обычно называется public_html или htdocs). Удаленный сервер в Файлзиле отображается справа, а слева отображается содержимое вашего компьютера.
Если бэкап планируете делать регулярно, то советую создать на жестком диске компьютера папку с «говорящим» названием, а внутри нее каталоги с названиями ваших проектов. Внутри этих каталогов можно создавать папки с текущей датой, в которые и будут копироваться файлы вашего веб-проекта. Благодаря этому потом будет проще ориентироваться в резервных копиях и удалять сильно устаревшие для освобождения места.
Теперь открываем в левой части FileZilla папку, куда будет осуществляться резервное копирование, а в правой части — корневую папку вебсайта. Советую включить в настройках этой программы возможность показывать скрытые файлы: в верхнем меню выберете пункт «Сервер» — «Принудительно отображать скрытые файлы» .
Это нужно для того, чтобы в ваш бэкап попали и скрытые файлики, такие, например, как.htaccess. Далее вы выделяете все объекты вашего сайта в корневой директории, удерживая кнопку SHift на клавиатуре. Щелкаете по выделенным объектам правой кнопкой мыши и выбираете из контекстного меню пункт «Скачать» .

Начнется резервное копирование файлов, которое может занять довольно продолжительное время — зависит от количества и общего веса копируемых объектов, а так же от и скорости работы сервера. Но вам вовсе не обязательно наблюдать за процессом создания бэкапа. Во время копирования вы можете заниматься своими делами, не закрывая Файлзилу, конечно же.
По окончанию процесса вам лучше всего будет запаковать все скачанное в один архив , ибо это может существенно уменьшить объем и количество хранимых объектов. После архивации вы оставляете только один архив, а все скачанное удаляете — будет все красиво и аккуратно. Для восстановления файлов сайта из такого бэкапа: его нужно будет распаковать и скопировать содержимое архива на сервер, способом аналогичным описанному выше.
Правда, если вы запаковали файлы в архив ZIP, то его можно будет загрузить на сервер, а уже там распаковать (тут описано, как ). Но при этом могут возникнуть некоторые неприятности с последующим , которые можно решить PHP средствами (читайте по ссылке про права доступа и изменение Cmod программным способом).
Как сделать бэкап базы данных с помощью phpMyAdmin
Давайте посмотрим, как сделать резервную копию базы данных с помощью скрипта phpMyAdmin. Доступ к нему можно получить из панели управления вашего хостинга. Если у вас , то для того, чтобы запустить phpMyAdmin, нужно пройти по следующему пути: находите на главной странице cPanel область под названием «Базы данных» и щелкаете там по иконке этого скрипта.

Если на вашем хостинге нет доступа к этому скрипту, то вы можете сами в корневую папку вашего сайта и получить через него доступ к своей базе данных. Скачать программу можно отсюда .
Скачав на свой компьютер архив, вы должны его распаковать и залить получившуюся папку (можно для простоты ее предварительно переименовать просто в phpmyadmin) в корневую директорию. В общем-то и все. Теперь останется только ввести в адресной строке вашего браузера следующий Урл: http://vash_sait.ru/phpmyadmin
В любом случае у вас откроется окно программы ПхпМайАдмин, с помощью которой мы сможем с легкостью осуществить резервное копирование баз данных своего проекта. Это главная страница программы (у меня на некоторых сайтах стоит несколько устаревшая версия, но я к ней просто привык):

Если вы находитесь на какой-либо другой странице phpMyAdmin, то для того, чтобы попасть на главную, нужно нажать на домик выделенный на рисунке. На одном аккаунте у хостера у вас может быть много БД и поэтому вы должны сначала выбрать из левого меню ту базу , резервное копирование которой вы хотите осуществить.

Список БД вы можете увидеть в окне программы слева (под иконкой домика). Для того, чтобы сделать бэкап базы данных вам нужно будет щелкнуть по вкладке «Экспорт» над списком таблиц.

Внизу открывшейся страницы поставьте галочку «gzip» . И нажмите кнопку «ok».

Правда, это в старой (удобной) версии скрипта. Сейчас же, по умолчанию вам предлагают быстро скачать базу без сжатия, а если хотите что-то настроить (в том числе и активировать ее gzip сжатие на лету), то нужно будет переставить галочку в поле «Обычный» и выбрать gzip среди множества других настроек, что не очень удобно на мой взгляд.

В результате, через некоторое время (которое зависит от скорости работы сервера, его загруженности и размера вашей БД) откроется стандартный диалог копирования, в котором вы должны выбрать место сохранения бэкапа этой БД.
Восстановление базы данных из созданной ранее резервной копии
Чтобы восстановить из бэкапа базу данных нужно действовать следующим образом. Во-первых, вы должны очистить уже имеющуюся БД от всех таблиц. Для этого вы входите в программу phpMyAdmin, выбираете в левой колонке нужную БД, которую требуется восстановить.
В открывшемся окне с таблицами этой базы данных опускаетесь в самый низ и под списком таблиц нажимаете на «Отметить все» . Затем, опять же внизу страницы, выбираем из выпадающего списка «С отмеченными» пункт «Удалить» .

У вас откроется окно со списком всех удаляемых таблиц. Вы нажимаете на кнопку «Да».
Теперь можно восстановить базу данных из сделанной ранее резервной копии. Для этого выбираем закладку «Импорт» :

В открывшемся окне нажимаете на кнопку «Выберете файл» и находите сделанный ранее бэкап этой БД у себя на жестком диске. Жмете на кнопку «Вперед» (или «OK» в старых версиях скрипта) внизу страницы и ждете, когда загрузка закончится (время опять же зависит от скорости сервера и размера базы данных). Все.
Имея на своем компьютере актуальные резервные копии файлов и бэкапы базы данных вы можете спать спокойно. Их так же можно будет использовать при переносе сайта на другой хостинг.
Перенос сайта на новый хостинг
Итак, как же нам осуществить перенос сайта на новое место жительства? После покупки хостинга вам предоставят данные для доступа к серверу хостинга по FTP, которые вы и введете в программу Файлзила для получения доступа к серверу.
Предварительно распакуйте бэкап данных на компьютере и закиньте их в корневую папку по аналогии с описанным выше процессом. Не дожидаясь окончания копирования файлов вы можете приступать к восстановлению таблиц базы данных из резервной копии, сделанной на старом месте жительства вашего ресурса.
Но для этого нужно предварительно на новом хостинге (куда потом будут копироваться сохраненные вами таблицы). Как это сделать вы узнаете из статьи про phpMyAdmin, ссылку на которую я приводил чуть выше. Обратите внимание, что у вас, скорей всего, не получится выбрать имя для БД и ее пользователя такими же как и на предыдущем месте жительства. Дело в том, что на хостинге обычно добавляют к выбранному вами имени БД еще и ваш логин.
Поэтому, после окончания копирования файлов и БД, прежде, чем обращаться к сайту из браузера, следует внести соответствующие изменения в настройки движка вашего сайта . Для этого нужно будет опять же получить доступ к файлам сайта по FTP и внести изменения в конфигурационные файлы того или иного движка (Joomla, WordPress, SMF и др.). Рассмотрим настройки для каждого движка в отдельности.
Что нужно изменить в настройках WordPress при его переносе
Перенос блога на Вордпрессе потребует изменения следующих настроек. Нужно будет открыть на редактирование с помощью FileZilla файл WP-CONFIG.PHP , который находится в корневой директории на сервере. В нем нужно отредактировать строки, отвечающие за название БД и пользователя.
// ** Настройки MySQL - Вы можете получить их у вашего хостера ** // /** Имя БД для WordPress */ define("WP_CACHE", true); //Added by WP-Cache Manager define("DB_NAME", "введите сюда новое имя вашей базы данных"); /** MySQL имя пользователя */ define("DB_USER", "введите сюда новое имя пользователя"); /** MySQL пароль БД */ define("DB_PASSWORD", "anipiimaaxai"); /** MySQL сервер - иногда требуется изменять это значение, например, на Мастерхосте */ define("DB_HOST", "localhost"); /** Кодировка БД, используемая при создании таблиц. */ define("DB_CHARSET", "utf8"); /** Сопоставление БД. НЕ ИЗМЕНЯЙТЕ ЭТО ЗНАЧЕНИЕ. */ define("DB_COLLATE", "");
После редактирования сохраните этот файл обратно и можете считать, что перенос WordPress на новый хостинг успешно состоялся. В случае, если вы при переносе блога изменяете доменное имя, то для того, чтобы все заработало корректно, вам нужно будет открыть резервную копию БД с расширением SQL в текстовом редакторе (извлечь ее из архива gzip).
Далее, с помощью встроенного «поиска с заменой», найдите все упоминания старого Урла вашего блога и замените его новый адрес (например, vasy.ru на vova.ru). После этого сохраните файл с резервной копией БД и осуществите его «Импорт» в программе phpMyAdmin.
После того, как вы зайдете в админку Вордпресса, нужно будет еще прописать правильный абсолютный путь к объектам вашего блога (он изменился, т.к. вы перенесли WordPress на другой хостинг). Задается абсолютный путь через параметр UPLOAD_PATH в глобальных настройках WP. Попасть в эти настройки можно, добавив к Урлу главной страницы следующий путь:
/wp-admin/options.php
Для адреса моего блога получится так:
Https://сайт/wp-admin/options.php
Но предварительно нужно обязательно залогиниться в админке WordPress. читайте по приведенной ссылке.
Что нужно изменить в настройках Joomla при смене хостинга
Перенос на другой хостинг сайта на Joomla потребует изменения следующих настроек. Вам нужно будет открыть на редактирование CONFIGURATION.PHP в корневой папке сервера. Найдите в нем строки, отвечающие за получение доступа к БД:
Var $user = "введите сюда новое имя пользователя"; var $db = "введите сюда новое имя вашей базы данных";
Кроме этого вам нужно будет еще изменить там абсолютный путь к папкам для хранения логов и временных файлов в Joomla. Изменить его нужно в этих строках:
Var $log_path = "/home/xxxxx/public_html/logs"; var $tmp_path = "/home/xxxx/public_html/tmp";
Перенос форума SMF на новый хостинг
Перенос форума на SMF потребует изменения некоторых настроек. Нужно будет открыть на редактирование SETTINGS.PHP из корневой папки форума. Так же, как и в случае с Joomla, здесь тоже нужно будет не только изменить имя БД и пользователя SMF, но и абсолютные пути до папки форума и папки SOURCES форума.
########## Database Info ########## $db_server = "localhost"; $db_name = "введите сюда новое имя вашей базы данных"; $db_user = "введите сюда новое имя пользователя"; $db_passwd = "hoighaebaeto"; $db_prefix = "smf_"; $db_persist = 0; $db_error_send = 1; ########## Directories/Files ########## # Note: These directories do not have to be changed unless you move things. $boarddir = "/home/xxxx/public_html/forum"; # The absolute path to the forum"s folder. (not just "."!) $sourcedir = "/home/xxxx/public_html/forum/Sources"; # Path to the Sources directory.Но кроме этого, после переноса SMF на новый хостинг, вам нужно будет изменить абсолютный путь к папке, установленной в данный момент . Для этого нужно будет зайти в админку форума, выбрать из левой колонки пункт «Текущая тема оформления». В открывшемся окне в области «Папка темы оформления» вы прописываете абсолютный путь к нужной папке.
Как начать работать с сайтом сразу после его переноса на новый хостинг
Вы , прикрепили к нему ваше (сайт, в моем случае). Или же вы, в соответствии с описанным выше, осуществили перенос. В принципе, неважно, но вам в любом случае придется связать новый сервер с доменом. Для этого вам вашего нового хоста в панели управления вашего регистратора (там, где вы купили доменное имя).
Адреса DNS серверов вы можете посмотреть в письме, которое вам пришлет ваш новый хостер. Где именно в панели регистратора нужно вводить эти DNS , однозначно сказать трудно, но это должно быть не глубоко закопано и лежать на виду. В крайнем случае обратитесь к службе техподдержки.

Так вот, несмотря на успешный перенос сайта на новый хост, вам еще придется подождать от нескольких часов до пары суток , пока ваш домен делегируется. Пока этот процесс не завершится, ваш ресурс не будет доступен на новом месте жительства.
Иногда владелец хостинга может указать в письме технический адрес, по которому вы сможете обращаться к вашему ресурсу, пока обновятся записи на всех DNS серверах интернета. Но это происходит не всегда. К тому же, например, для WordPress технический адрес не позволит вам полноценно начать работать с только что перенесенным блогом, ибо этот движок жестко привязан к доменному имени.
Но владелец хоста в письме всегда указывает IP адрес вашего нового сервера. Используя его, можно получить доступ к своему ресурсу не ожидая прописывания ДНС . Но доступ, в этом случае, получите только вы и только на том компьютере, где вы произведете описанные ниже настройки. Итак, нужно проделать следующее:
- с помощью любого файлового менеджера открыть для редактирования (по этой ссылке вы найдет подробную статью по тому, где находится этот файл, как его найти в Windows 7 и что в нем должно быть прописано), расположенный по следующему пути: c:\Windows\System32\drivers\etc\hosts
- в конце содержимого HOSTS нужно дописать строчку: 109.77.43.4 сайт где в начале идет IP адрес нового сервера, а после него, через пробел, домен
- сохраните этот файл и можете смело набирать в браузере адрес того ресурса, перенос которого вы только что осуществили (может понадобиться сброс ДНС-кэша на компьютере — читайте об этом в приведенной чуть выше статье про файл Хостс)
Таким образом, не дожидаясь делегирования домена, вы уже можете проверить работоспособность перенесенного ресурса и, при необходимости, все исправить до того, как он станет доступен всем остальным посетителям. После того, как домен делегируется, вам нужно будет удалить добавленную строку в HOSTS .
Можете также посмотреть на видео по теме от известного в рунете сайтостроителя:
Ну, и подборку видеоуроков по перенос сайта Joomla CMS на хостинг советую посмотреть. Они будут воспроизводиться один за другим автоматом, а если хотите, то можете переключаться на следующий урок с помощью соответствующей кнопки на панели плеера или выбрать нужный урок из выпадающего меню в верхнем левом углу окна плеера:

Приятного просмотра!
Удачи вам! До скорых встреч на страницах блога сайт
посмотреть еще ролики можно перейдя на");">

Вам может быть интересно
Серверы баз данных - одни из ключевых в любой организации. Именно они хранят информацию и предоставляют выдачу по запросу, и крайне важно сохранить БД в любой ситуации. Базовая поставка обычно включает нужные утилиты, но админу, не сталкивавшемуся до этого с БД, придется некоторое время разбираться с особенностями работы, чтобы обеспечить автоматизацию.
Виды бэкапов баз данных
Для начала разберемся с тем, какие вообще бывают бэкапы. Сервер баз данных не является обычным десктопным приложением, и, чтобы обеспечить выполнение всех свойств ACID (Atomic, Consistency, Isolated, Durable), используется ряд технологий, а поэтому создание и восстановление БД из архива имеет свои особенности. Существуют три различных подхода к резервному копированию данных, каждый из которых имеет свои плюсы и минусы.
При логическом, или SQL, бэкапе (pg_dump, mysqldump, SQLCMD) создается мгновенный снимок содержимого базы с учетом транзакционной целостности и сохраняется в виде файла с SQL-командами (можно выбрать всю базу или отдельные таблицы), при помощи которого можно воссоздать базу данных на другом сервере. На это требуется время (особенно для больших баз) для сохранения и восстановления, поэтому очень часто эту операцию выполнять нельзя и ее производят во время минимальной нагрузки (например, ночью). При восстановлении администратору необходимо будет выполнить несколько команд, чтобы подготовить все необходимое (создать пустую базу данных, учетные записи и прочее).
Физический бэкап (уровня файловой системы) - копирование файлов, которые СУБД использует для хранения данных в базе данных. Но при простом копировании игнорируются блокировки и транзакции, которые, скорее всего, будут неправильно сохранены и нарушены. При попытке присоединить этот файл он будет в несогласованном состоянии и приведет к ошибкам. Чтобы получить актуальный бэкап, базу данных нужно остановить (можно уменьшить время простоя, использовав два раза rsync - вначале на работающей, потом на остановленной). Недостаток этого метода очевиден - нельзя восстановить определенные данные, только всю базу данных. При старте БД, восстановленной из архива файловой системы, нужно будет провести проверку на целостность. Здесь используются разные вспомогательные технологии. Например, в PostgreSQL логи упреждающей журнализации WAL (Write Ahead Logs) и специальная функция (Point in Time Recovery - PITR), позволяющая вернуться к определенному состоянию базы. С их помощью легко реализуется третий сценарий, когда бэкап уровня файловой системы объединяется с резервной копией WAL-файлов. Вначале восстанавливаем файлы резервной копии файловой системы, а затем при помощи WAL база приводится к актуальному состоянию. Это чуть более сложный подход для администрирования, но зато нет проблем с целостностью БД и восстановлением баз до определенного времени.
Логический бэкап используется в тех случаях, когда необходимо одноразово сделать полную копию базы или в повседневной эксплуатации для создания копии не потребуется много времени или места. Когда же выгрузка баз занимает много времени, следует обратить внимание на физическое архивирование.
Barman
Лицензия: GNU GPL
Поддерживаемые СУБД: PostgreSQL
PostgreSQL поддерживает возможности физического и логического бэкапа, добавляя к ним еще один уровень WAL (см. врезку), который можно назвать непрерывным копированием. Но управлять при помощи штатных инструментов несколькими серверами не очень удобно даже админу со стажем, а в случае сбоя счет идет на секунды.
Barman (backup and recovery manager) - внутренняя разработка компании 2ndQuadrant, предоставляющей услуги на базе PostgreSQL. Предназначен для физического бэкапа PostgreSQL (логический не поддерживает), архивирования WAL и быстрого восстановления после сбоев. Поддерживаются удаленный бэкап и восстановление нескольких серверов, функции point-in-time-recovery (PITR), управление WAL. Для копирования и подачи команд на удаленный узел используется SSH, синхронизация и бэкап при помощи rsync позволяет сократить трафик. Также Barman интегрируется со стандартными утилитами bzip2, gzip, tar и подобными. В принципе, можно использовать любую программу сжатия и архивирования, интеграция не займет много времени. Реализованы различные сервисные и диагностические функции, позволяющие контролировать состояние сервисов и регулировать полосу пропускания. Поддерживаются Pre/Post-скрипты.
Barman написан на Python, управление политиками резервного копирования производится при помощи понятного INI-файла barman.conf, который может находиться в /etc или домашнем каталоге пользователя. В поставке идет готовый шаблон с подробными комментариями внутри. Работает только на *nix-системах. Для установки в RHEL, CentOS и Scientific Linux следует подключить EPEL - репозиторий, в котором содержатся дополнительные пакеты. В распоряжении пользователей Debian/Ubuntu официальный репозиторий:
$ sudo apt-get install barman
В репозитории не всегда последняя версия, для ее установки придется обратиться к исходным текстам. Зависимостей немного, и разобраться в процессе несложно.
Sypex Dumper
Лицензия: BSD
Поддерживаемые СУБД: MySQL
Вместе с MySQL поставляются утилиты mysqldump, mysqlhotcopy, позволяющие легко создать дамп базы данных, они хорошо документированы, и в интернете можно найти большое количество готовых примеров и фронтендов. Последние позволяют новичку быстро приступить к работе. Sypex Dumper представляет собой PHP-скрипт, позволяющий легко создать и восстановить копию базы данных MySQL. Создавался для работы с большими базами данных, работает очень быстро, понятен и удобен в использовании. Умеет работать с объектами MySQL - представлениями, процедурами, функциями, триггерами и событиями.
Еще один плюс, в отличие от других инструментов, при экспорте производящих перекодирование в UTF-8, - в Dumper экспорт производится в родной кодировке. Результирующий файл занимает меньше места, а сам процесс происходит быстрее. В одном дампе могут быть объекты с разными кодировками. Причем легко импорт/экспорт произвести в несколько этапов, останавливая процесс во время нагрузки. При возобновлении процедура начнется с места остановки. При восстановлении поддерживается четыре варианта:
- CREATE + INSERT - стандартный режим восстановления;
- TRUNCATE + INSERT - меньше времени на создание таблиц;
- REPLACE - восстанавливаем в рабочей базе старые данные, не затирая новые;
- INSERT IGNORE - добавляем в базу удаленные или новые данные, не трогая существующие.
Поддерживается сжатие копии (gzip или bzip2), автоудаление старых бэкапов, реализован просмотр содержимого дамп-файла, восстановление только структуры таблиц. Имеются и сервисные функции по управлению БД (создание, удаление, проверка, восстановление БД, оптимизация, очистка таблиц, работа с индексами и другое), а также файл-менеджер, позволяющий копировать файлы на сервер.

Управление производится при помощи веб-браузера, интерфейс с использование AJAX локализован из коробки и создает впечатление работы с настольным приложением. Также возможно запускать задания из консоли и по расписанию (через cron).
Для работы Dumper понадобится классический L|WAMP-сервер, установка обычная для всех приложений, написанных на PHP (копируем файлы и устанавливаем права), и не будет сложной даже для новичка. Проект предоставляет подробную документацию и видеоуроки, демонстрирующие работу с Sypex Dumper.
Есть две редакции: Sypex Dumper (бесплатно) и Pro (10 долларов). Вторая имеет больше возможностей, все отличия приведены на сайте.
SQL Backup And FTP
Лицензия:
Поддерживаемые СУБД: MS SQL Server
MS SQL Server - одно из популярных решений, а потому встречается достаточно часто. Задание резервного копирования создается при помощи среды SQL Server Management Studio, собственно Transact-SQL и командлетов модуля SQL PowerShell (Backup-SqlDatabase). На сайте MS можно найти просто огромное количество документации, которая позволяет разобраться с процессом. Документация хотя и полная, но очень специфическая, а информация в интернете часто противоречит друг другу. Новичку действительно вначале потребуется потренироваться, «набив руку», поэтому, даже несмотря на все сказанное, сторонним разработчикам есть где развернуться. К тому же бесплатная версия SQL Server Express не может похвастаться встроенными инструментами для резервного копирования. Для более ранних версий MS SQL (до 2008) можно найти бесплатные утилиты, например SQL Server backup , но в большинстве подобные проекты уже коммерциализировались, хотя и предлагают всю функциональность часто за символическую сумму.

Например, разработка SQL Backup And FTP и One-Click SQL Restore соответствует принципу «настроил и забыл». Обладая очень простым и понятным интерфейсом, они позволяют создавать копии баз данных MS SQL Server (включая Express) и Azure, сохранять зашифрованные и сжатые файлы на FTP и облачных сервисах (Dropbox, Box, Google Drive, MS SkyDrive или Amazon S3), результат можно тут же просмотреть. Возможен запуск процесса как вручную, так и по расписанию, отправка сообщения о результате задания по email, запуск пользовательских скриптов.
Поддерживаются все варианты бэкапа: полный, дифференциальный, журнал транзакций, копирование папки с файлами и многое другое. Старые резервные копии удаляются автоматически. Для подключения к виртуальному узлу используется SQL Management Studio, хотя здесь могут быть нюансы и это будет работать не во всех таких конфигурациях. Для загрузки предлагается пять версий - от бесплатной Free до навороченной Prof Lifetime (на момент написания этих строк стоила всего 149 долларов). Функционала Free вполне достаточно для небольших сетей, в которых установлено один-два SQL-сервера, все основные функции активны. Ограничено количество резервных БД, возможность отправки файлов на Google Drive и SkyDrive и шифрование файлов. Интерфейс хотя и не локализован, но очень прост и понятен даже новичку. Нужно лишь подключиться к SQL-серверу, после чего будет выведен список баз данных, следует отметить нужные, настроить доступ к удаленным ресурсам и указать время выполнения задания. И все это в одном окне.
Но есть одно «но». Сама программа не предназначена для восстановления архивов. Для этого предлагается отдельная бесплатная утилита One-Click SQL Restore, понимающая и формат, созданный командой BACKUP DATABASE. Админу необходимо лишь указать архив и сервер, на который восстановить данные, и нажать одну кнопку. Но в более сложных сценариях придется использовать RESTORE.

Особенности бэкапа MS SQL Server
Создание резервной копии и восстановление СУБД имеет свои отличия, которые нужно учитывать, особенно их много при переносе архива на другой сервер. Для примера разберем некоторые нюансы MS SQL Server. Для архивирования при помощи Transact-SQL следует использовать команду BACKUP DATABASE (есть и разностная DIFFERENTIAL) и журнал транзакций BACKUP LOG.
Если резервная копия разворачивается на другом сервере, нужно убедиться, что присутствуют те же самые логические диски. Как вариант - можно вручную прописать правильные пути для файлов базы данных, используя опцию WITH MOVE команды RESTORE DATABASE.
Простая ситуация - бэкап и перенос баз на другие версии SQL Server. Эта операция поддерживается, но в случае SQL Server будет работать, если версия сервера, на которой разворачивается копия, такая же или новее, чем та, на которой она создавалась. Причем есть ограничение: новее не более чем на две версии. После восстановления БД будет находиться в режиме совместимости с той версией, с которой осуществлялся переход, то есть новые функции будут недоступны. Это легко поправить, изменив COMPATIBILITY_LEVEL. Можно это сделать при помощи GUI или SQL.
ALTER DATABASE MyDB SET COMPATIBILITY_LEVEL = 110;
Определить, на какой версии была создана копия, можно, просмотрев заголовок файла архива. Чтобы не экспериментировать, при переходе на новую версию SQL Server следует запустить бесплатную утилиту Microsoft Upgrade Advisor.
Iperius
Лицензия: коммерческая, есть версия Free
Поддерживаемые СУБД: Oracle 9–11, XE, MySQL, MariaDB, PostgreSQL и MS SQL Server
Когда приходится управлять несколькими типами СУБД, без комбайнов не обойтись. Выбор большой. Например, Iperius - легкая, очень простая в использовании и одновременная мощная программа для резервного копирования файлов, имеющая функцию горячего резервирования баз данных без прерывания в работе или блокирования. Обеспечивает полный или инкрементальный бэкап. Может создавать полные образы дисков для автоматической переустановки всей системы. Поддерживает резервное копирование на NAS, USB-устройства, стример, FTP/FTPS, Google Drive, Dropbox и SkyDrive. Поддерживает сжатие zip без ограничения в размере файлов и AES256-шифрование, запуск внешних скриптов и программ. Включает весьма функциональный планировщик заданий, возможно параллельное или последовательное выполнение нескольких заданий, результат отправляется на email. Поддерживаются многочисленные фильтры, переменные для персонализации путей и настроек.
Возможность закачки по FTP позволяет легко обновлять информацию на нескольких веб-сайтах. Открытые файлы резервируются при помощи технологии VSS (теневого копирования томов), что позволяет производить горячий бэкап не только файлов СУБД, но и других приложений. Для Oracle также задействуется средство организации резервного копирования и восстановления данных RMAN (Recovery Manager). Чтобы не перегружать канал, есть возможность настройки полосы пропускания. Управление резервированием и восстановлением производится при помощи локальной и веб-консоли. Все функции на виду, поэтому для настройки задания потребуется лишь понимание процесса, в документацию заглядывать даже не придется. Просто следуем подсказкам мастера. Также можно отметить менеджер учетных записей, что очень удобно при большом количестве систем.
Базовые функции предлагаются бесплатно, но возможность резервирования БД заложена только в версиях Advanced DB и Full. Поддерживается установка от XP до Windows Server 2012.
Handy Backup
Лицензия: коммерческая
Поддерживаемые СУБД: Oracle, MySQL, IBM DB2 (7–9.5) и MS SQL Server
Одна из самых мощных систем управления реляционными базами данных - IBM DB2, имеющая уникальные функции по масштабированию и поддерживающая множество платформ. Поставляется в нескольких редакциях, которые построены на одной базе и отличаются функционально. Архитектура баз данных DB2 позволяет управлять практически всеми типами данных: документами, XML, медиафайлами и так далее. Особо популярна бесплатная DB2 Express-C. Бэкап очень прост:
Db2 backup db sample
Или снапшот, использующий функцию Advanced Copy Services (ACS):
Db2 backup db sample use snapshot
Но нужно помнить, что в случае снимков мы не можем восстанавливать (db2 recover db) отдельные таблицы. Есть и возможности по автоматическому бэкапу, и многое другое. Продукты хорошо документированы, хотя в русскоязычном интернете руководства встречаются редко. Также далеко не во всех специальных решениях можно найти поддержку DB2.
Например, Handy Backup позволяет выполнять бэкап нескольких типов серверов баз данных и сохранять файлы практически на любой носитель (жесткий диск, CD/DVD, облачное и сетевое хранилище, FTP/S, WebDAV и другие). Возможен бэкап баз данных через ODBC (только таблицы). Это одно из немногих решений, поддерживающих DB2, и к тому же имеет логотип «Ready for IBM DB2 Data Server Software». Вся процедура выполняется при помощи обычного мастера, в котором необходимо лишь выбрать нужный пункт и сформировать задачу. Сам процесс настройки настолько прост, что разобраться сможет и новичок. Можно создать несколько заданий, которые будут запускаться по расписанию. Результат фиксируется в журнале и отправляется по email. Во время работы задания остановка сервиса не требуется. Архив автоматически сжимается и шифруется, что гарантирует его безопасность.
Работу с DB2 поддерживают две версии Handy Backup - Office Expert (локальный) и Server Network (сетевой). Работает на компьютерах под управлением Win8/7/Vista/XP или 2012/2008/2003. Сам процесс развертывания несложен для любого админа.
Несмотря на то, что в наших предыдущих материалах мы уже касались вопроса резервного копирования баз Microsoft SQL Server, читательский отклик показал необходимость создания полноценного материала с более глубокой проработкой теоретической части. Действительно, выполненные с упором на практические инструкции статьи позволяют быстро настроить резервное копирование, но не объясняют причины выбора тех или иных настроек. Постараемся исправить этот пробел.
Модели восстановления
Перед тем как браться за настройку резервного копирования, следует выбрать модель восстановления. Для оптимального выбора следует оценить требования к восстановлению и критичность потери данных, сопоставив их с накладными расходами на реализацию той или иной модели.
Как известно, база данных MS SQL состоит из двух частей: собственно, базы данных и лога транзакций к ней. База данных содержит пользовательские и служебные данные на текущий момент времени, лог транзакций включает в себя историю всех изменений базы данных за определенный период, располагая логом транзакций мы можем откатить состояние базы на любой произвольный момент времени.
Для использования в производственных средах предлагается две модели восстановления: простая и полная . Существует также модель с неполным протоколированием , но она рекомендуется только как дополнение к полной модели на период крупномасштабных массовых операций, когда нет необходимости восстановления базы на определенный момент времени.
Простая модель предусматривает резервное копирование только базы данных, соответственно восстановить состояние БД мы можем только на момент создания резервной копии, все изменения в промежуток времени между созданием последней резервной копии и сбоем будут потеряны. В тоже время простая схема имеет небольшие накладные расходы: вам необходимо хранить только копии базы данных, лог транзакций при этом автоматически усекается и не растет в размерах. Также процесс восстановления наиболее прост и не занимает много времени.
Полная модель позволяет восстановить базу на любой произвольный момент времени, но требует, кроме резервных копий базы, хранить копии лога транзакций за весь период, для которого может потребоваться восстановление. При активной работе с базой размер лога транзакций, а, следовательно, и размер архивов, могут достигать больших размеров. Процесс восстановления также гораздо более сложен и продолжителен по времени.
При выборе модели восстановления следует сравнить затраты на восстановление с затратами на хранение резервных копий, также следует принять во внимание наличие и квалификацию персонала, который будет выполнять восстановление. Восстановление при полной модели требует от персонала определенной квалификации и знаний, тогда как при простой схеме достаточно будет следовать инструкции.
Для баз с небольшим объемом добавления информации может быть выгоднее использовать простую модель с большой частотой копий, которая позволит быстро восстановиться и продолжить работу, введя потерянные данные вручную. Полная модель в первую очередь должна использоваться там, где потеря данных недопустима, а их возможное восстановление сопряжено со значительными затратами.
Виды резервных копий
Полная копия базы данных - как следует из ее названия, представляет собой содержимое базы данных и часть активного лога транзакций за то время, которое формировалась резервная копия (т.е. сведения обо всех текущих и незавершенных транзакциях). Позволяет полностью восстановить базу данных на момент создания резервной копии.
Разностная копия базы данных - полная копия имеет один существенный недостаток, она содержит всю информацию базы данных. Если резервные копии нужно делать довольно часто, то сразу возникает вопрос неэкономного использования дискового пространства, так как большую часть хранилища будут занимать одинаковые данные. Для устранения этого недостатка можно использовать разностные копии базы данных, которые содержат только изменившуюся со времени последнего полного копирования информацию.
 Обращаем внимание, разностная копия - это данные от момента последнего полного
копирования, т.е. каждая последующая разностная копия содержит в себе данные предыдущей (но при этом они могут быть изменены) и размер копии будет постоянно расти. Для восстановления достаточно одной полной и одной разностной копии, обычно последней. Количество разностных копий следует выбирать исходя из прироста их размера, как только размер разностной копии сравнится с размером половины полной, имеет смысл сделать новую полную копию.
Обращаем внимание, разностная копия - это данные от момента последнего полного
копирования, т.е. каждая последующая разностная копия содержит в себе данные предыдущей (но при этом они могут быть изменены) и размер копии будет постоянно расти. Для восстановления достаточно одной полной и одной разностной копии, обычно последней. Количество разностных копий следует выбирать исходя из прироста их размера, как только размер разностной копии сравнится с размером половины полной, имеет смысл сделать новую полную копию.
Резервная копия журнала транзакций - применяется только при полной модели восстановления и содержит копию журнала транзакций начиная с момента создания предыдущей копии.

Важно помнить следующий момент - копии журнала транзакций никак не связаны с копиями базы данных и не содержат информацию предыдущих копий, поэтому для восстановления базы вам необходимо иметь непрерывную цепочку копий того периода, в течении которого вы хотите иметь возможность откатывать состояние базы. При этом момент последнего успешного копирования должен быть внутри этого периода.
Посмотрим на рисунок выше, если будет утрачена первая копия файла журнала, то вы сможете восстановить состояние базы только на момент полного копирования, что будет аналогично простой модели восстановления, восстановить состояние базы на любой момент времени вы сможете только после следующего разностного (или полного) копирования, при условии, что цепочка копий журналов начиная с предшествующего копированию базы и далее будет непрерывна (на рисунке - от третьего и далее).
Журнал транзакций
Для понимания процессов восстановления и назначения разных видов резервных копий следует более подробно рассмотреть устройство и работу журнала транзакций. Транзакция - это минимально возможная логическая операция, которая имеет смысл и может быть выполнена только полностью. Такой подход обеспечивает целостность и непротиворечивость данных при любых ситуациях, так как промежуточное состояние операции недопустимо. Для контроля над любыми изменениями в базе предназначен журнал транзакций.
При выполнении любой операции в журнал транзакций добавляется запись о начале транзакции, каждой записи присваивается уникальный номер (LSN) из неразрывной последовательности, при любом изменении данных в журнал вносится соответствующая запись, а после завершения операции в журнале появляется отметка о закрытии (фиксации) транзакции.
 При каждом запуске система анализирует журнал транзакций и откатывает все незафиксированные транзакции, одновременно с этим происходит накат изменений, которые зафиксированы в журнале, но не были записаны на диск. Это дает возможность использовать кэширование и отложенную запись, не опасаясь за целостность данных даже при отсутствии систем резервного питания.
При каждом запуске система анализирует журнал транзакций и откатывает все незафиксированные транзакции, одновременно с этим происходит накат изменений, которые зафиксированы в журнале, но не были записаны на диск. Это дает возможность использовать кэширование и отложенную запись, не опасаясь за целостность данных даже при отсутствии систем резервного питания.
Та часть журнала, которая содержит активные транзакции и используется для восстановления данных называется активной частью журнала. Она начинается с номера, который называется минимальным номером восстановления (MinLSN).
В простейшем случае MinLSN - это номер записи первой незавершенной транзакции. Если посмотреть на рисунок выше, то открыв синюю транзакцию мы получим MinLSN равную 321, после ее фиксации в записи 324, номер MinLSN изменится на 323, что будет соответствовать номеру зеленой, еще не зафиксированной, транзакции.
На практике все немного сложнее, например, данные закрытой синей транзакции могут быть еще не сброшены на диск и перемещение MinLSN на 323 сделает восстановление этой операции невозможной. Для того, чтобы избежать таких ситуации было введено понятие контрольной точки. Контрольная точка создается автоматически при наступлении следующих условий:
- При явном выполнении инструкции CHECKPOINT. Контрольная точка срабатывает в текущей базе данных соединения.
- При выполнении в базе данных операции с минимальной регистрацией, например, при выполнении операции массового копирования для базы данных, на которую распространяется модель восстановления с неполным протоколированием.
- При добавлении или удалении файлов баз данных с использованием инструкции ALTER DATABASE.
- При остановке экземпляра SQL Server с помощью инструкции SHUTDOWN или при остановке службы SQL Server (MSSQLSERVER). И в том, и в другом случае будет создана контрольная точка каждой базы данных в экземпляре SQL Server.
- Если экземпляр SQL Server периодически создает в каждой базе данных автоматические контрольные точки для сокращения времени восстановления базы данных.
- При создании резервной копии базы данных.
- При выполнении действия, требующего отключения базы данных. Примерами могут служить присвоение параметру AUTO_CLOSE значения ON и закрытие последнего соединения пользователя с базой данных или изменение параметра базы данных, требующее перезапуска базы данных.
В зависимости от того, какое событие произошло раньше, MinLSN будет присвоено значение либо номера записи контрольной точки, либо начала самой старой незавершенной транзакции.
Усечение журнала транзакций
Журнал транзакций, как и любой журнал, требует периодической очистки от устаревших записей, иначе он разрастется и займет все доступное место. Учитывая, что при активной работе с базой размер лога транзакций может значительно превышать размер базы, то этот вопрос актуален для многих администраторов.
Физически файл журнала транзакций является контейнером для виртуальных журналов, которые последовательно заполняются по мере роста лога. Логический журнал, содержащий запись MinLSN является началом активного журнала, предшествующие ему логические журналы являются неактивными и не требуются для автоматического восстановления базы.
 Если выбрана простая модель восстановления, то при достижении логическими журналами размера равного 70% физического файла происходит автоматическая очистка неактивной части журнала, т.н. усечение. Однако это не приводит к уменьшению физического файла журнала, усекаются только логические журналы, которые после этой операции могут использоваться повторно.
Если выбрана простая модель восстановления, то при достижении логическими журналами размера равного 70% физического файла происходит автоматическая очистка неактивной части журнала, т.н. усечение. Однако это не приводит к уменьшению физического файла журнала, усекаются только логические журналы, которые после этой операции могут использоваться повторно.
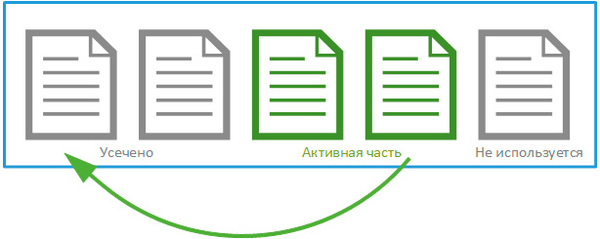
Если количество транзакций велико и к моменту достижения 70% размера физического файла не окажется неактивных логических журналов, то размер физического файла будет увеличен.
 Таким образом файл лога транзакций при простой модели восстановления будет расти согласно активности работы с базой до тех пор, пока не будет надежно вмещать всю активную часть журнала. После чего его рост прекратится.
Таким образом файл лога транзакций при простой модели восстановления будет расти согласно активности работы с базой до тех пор, пока не будет надежно вмещать всю активную часть журнала. После чего его рост прекратится.
При полной модели неактивную часть журнала нельзя усечь до тех пор, пока она полностью не попадет в резервную копию. Усечение журнала производится при условии, что выполнена резервная копия журнала транзакций, после чего была создана контрольная точка.
Неправильная настройка резервного копирования журнала транзакций при полной модели способно привести к неконтролируемому росту файла журнала, что часто составляет проблему для неопытных администраторов. Также часто попадаются советы по ручному усечению журнала транзакций. При полной модели восстановления делать этого не следует категорически, так как тем самым вы нарушите целостность цепочки копий журнала и сможете восстановить базу только на момент создания копий, что будет соответствовать простой модели.
В этом случае самое время вспомнить то, о чем мы говорили в начале статьи, если затраты на полную модель превышают затраты на восстановление следует отдать предпочтение простой модели.
Простая модель восстановления
Теперь, после получения необходимого минимума знаний, можно перейти к более подробному рассмотрению моделей восстановления. Начнем с простой. Допустим, на момент сбоя у нас имеется одна полная и две разностные копии:
 Резервное копирование выполнялось раз в сутки и последняя копия была создана ночью с 21-го на 22-е. Сбой происходит вечером 22-го до создания очередной копии. В этом случае нам потребуется последовательно восстановить полную и последнюю разностные копии, при этом данные за последний рабочий день будут утеряны. Если по каким-либо причинам копия от 21-го также окажется повреждена, то мы можем восстановить предыдущую копию, потеряв еще день работы, в тоже время повреждение копии за 20-е число никак не помешает успешно восстановить данные на вечер 21-го, при наличии соответствующей копии.
Резервное копирование выполнялось раз в сутки и последняя копия была создана ночью с 21-го на 22-е. Сбой происходит вечером 22-го до создания очередной копии. В этом случае нам потребуется последовательно восстановить полную и последнюю разностные копии, при этом данные за последний рабочий день будут утеряны. Если по каким-либо причинам копия от 21-го также окажется повреждена, то мы можем восстановить предыдущую копию, потеряв еще день работы, в тоже время повреждение копии за 20-е число никак не помешает успешно восстановить данные на вечер 21-го, при наличии соответствующей копии.
Полная модель восстановления
Рассмотрим аналогичную ситуацию, но с применением полной модели восстановления. Резервные копии у нас также делаются ежесуточно, по принципу полная + разностные, а также несколько раз в сутки копируется лог транзакций.
 Процесс восстановления в этом случае будет более сложен. Прежде всего потребуется создать вручную резервную копию заключительного фрагмента журнала (показана красным), т.е. часть журнала с момента прошлого создания копии и до аварии.
Процесс восстановления в этом случае будет более сложен. Прежде всего потребуется создать вручную резервную копию заключительного фрагмента журнала (показана красным), т.е. часть журнала с момента прошлого создания копии и до аварии.
Если этого не сделать, то восстановить базу можно будет только до состояния на момент создания последней копии журнала транзакций.
При этом повреждение файла копии журнала за предыдущий день не помешает нам восстановить актуальное состояние базы, но ограничит нас моментом создания последней копии, т.е. текущими сутками.
Затем последовательно восстанавливаем полную и разностную копию и цепочку копий журнала, созданную после последнего резервного копирования, последней восстанавливаем копию заключительного фрагмента журнала, что даст нам возможность восстановить базу прямо на момент аварии или произвольный, предшествовавший ему.
Если последняя разностная копия будет повреждена, то в случае с простой моделью это приведет к потере еще одного рабочего дня, полная модель позволяет восстановить предпоследнюю копию, после чего нужно будет восстановить всю цепочку копий лога транзакций от момента предпоследней копии и до сбоя. Глубина восстановления зависит только от глубины непрерывной цепочки логов.
С другой стороны, если одна из копий лога транзакций будет повреждена, скажем, предпоследняя, то восстановить данные мы сможем только на момент последней резервной копии + период в неповрежденной цепочке копий журналов. Например, если журналы делались в 12, 14 и 16 часов и поврежден журнал, созданный в 14 часов, то располагая суточной копией мы сможем восстановить базу до момента окончания непрерывной цепочки, т.е. до 12 часов.
Теги:
Майкл Вандайн (Michael Vandine), главный технический консультант
Введение
Стратегия восстановления должна занимать должное место, чтобы предотвратить случайную потерю данных. Возможности по восстановлению данных должны находится на том же высоком уровне, что и средства резервного копирования.
Восстановление баз данных - это ответ администраторов данных на закон Мэрфи. Базы данных неизбежно повреждаются или теряются по разным причинам: из-за системных или аппаратных сбоев, ошибок операторов, неправильных или недопустимых данных, программных ошибок, компьютерных вирусов и природных катаклизмов.
Поскольку любая организация сильно зависит от своих баз данных, необходимо придерживаться правильной стратегии, чтобы быстро и точно восстановить базу данных после ее потери или повреждения. Кроме того, поскольку восстановление данных должно быть поставлено настолько же хорошо, как и их резервирование, эта стратегия также должна включать в себя согласованную систему резервного копирования данных.
Ниже описаны основные возможности, которые должны быть реализованы для обеспечения точного восстановления:
- Резервное копирование данных в объеме, достаточном для возвращения базы данных к согласованному состоянию, вне зависимости от ее текущего состояния.
- Регистрация транзакций и изменений базы данных.
- Восстановление базы данных с достаточным количеством возможностей для ее приведения в исходное рабочее состояние, с минимальными потерями данных и времени.
В данной статье описываются опции каждой из этих возможностей, доступные для баз данных SQLBase . Каждая из этих опций должна рассматриваться с учетом конкретной ситуации. Лучший выбор для конкретной операции необходимо делать на основе различных факторов, включая приемлемые потери данных или время простоя, объем доступного пространства на диске и размер базы данных.
Резервное копирование баз данных
Здесь описываются различные варианты создания резервных копий, призванные обеспечить возможности восстановления данных к требуемому состоянию.
Резервная копия состоит из базы данных (файл с расширением BKP) и всех log-файлов, требуемых для приведения BKP-файла к согласованному состоянию во время резервирования. Необходимо помнить, что вне зависимости от типа выполняемого резервного копирования резервируемые данные должны быть неповрежденными. Поэтому рекомендуется проверять базу данных ("check database") перед резервным копированием и проводить эту процедуру только тогда, когда база данных находится в устойчивом состоянии.
Резервирование может быть осуществлено либо в режиме онлайн, используя ПО резервного копирования SQLBase (сервер SQLBase запущен, а пользователи подключены к базе данных), либо в режиме оффлайн с помощью стандартных команд операционной системы, т.е. используя COPY (отключен сервер SQLBase либо демонтирована база данных), а затем команду "set nextlog". Наиболее часто используемый вариант - резервирование в режиме онлайн, поскольку для большинства операций очень сложно найти подходящее время, когда все пользователи отключены от всех баз данных, с тем чтобы можно было корректно завершить работу сервера SQLBase или демонтировать все базы данных. Это необходимо, потому что сервер SQLBase удерживает базу данных в виде открытого файла, начиная с момента подключения первого процесса и заканчивая демонтажем базы данных или выключением сервера SQLBase.
SQLBase использует log-файлы транзакций, чтобы фиксировать исходный и преобразованный вид записей изменений базы данных, а также в качестве регулярных контрольных точек управления транзакциями. Они используются для восстановления после сбоев (что выполняется автоматически после прерывания энергоснабжения, отказа сервера и т. д.), отката (если в базу данных были внесены ненужные изменения или сбой стал причиной отмены транзакции) и для восстановления данных (восстановления баз данных).
Следует обратить внимание, что база данных состоит из файла с расширением DBS и log-файлов. В случае удаления log-файлов база данных становится недоступной для использования! По умолчанию SQLBase автоматически удаляет log-файлы после их резервирования, или когда они не нужны для восстановления после сбоев или отката. Это поведение можно изменить, установив для базы данных параметр LOGBACKUP в положение ON с помощью интерфейса SQLTalk. При таком положении параметра log-файлы сохраняются до тех пор, пока не создается их резервная копия с помощью специальной команды "backup logs". Это единственный способ удаления log-файлов. Этот параметр должен находится в положении ON, если необходимо применить команды "backup database" или "backup logs". И наоборот, не нужно устанавливать этот параметр в данное положение, если нет намерений использовать команду "backup logs" или внедрять возможность "rollforward" (восстановление с повтором всех завершенных транзакций) в стратегию восстановления, т. е. если предполагается делать только "моментальные снимки".
Максимальный размер log-файлов, создаваемых для каждой базы данных, можно указать, задав параметр LOGFILESIZE с помощью SQLTalk (по умолчанию этот размер - 1 МБ). Сначала log-файлы имеют минимальный размер, а затем они растут в объеме до указанного предела. Если с помощью SQLTalk установить параметр LOGFILEPREALLOC в положение ON, то есть возможность создавать для каждой базы данных шаблоны log-файлов максимального размера. Если необходимо много log-файлов, можно установить их максимальный объем большим (скажем 5 МБ) и заранее назначить размер файлов. Это приведет к уменьшению числа операций ввода/вывода, необходимых для создания новых файлов или дописывания существующих.
Log-файлы могут быть удалены только после применения команды "release log" или "backup logs", и если они не являются "блокированными". Log-файл оказывается блокированным в следующих случаях:
- Текущая транзакция осуществляет запись в этот log-файл. Блокировка может быть снята с этого файла только после завершения или отката транзакции.
- Предпоследняя контрольная точка была создана при использовании данного или предыдущего log-файла. Например, если контрольная точка была создана в 6.log, то этот log-файл и все последующие будут блокированы. В этом случае блокировку можно снять с помощью команды "release log".
- Параметр LOGBACKUP находится в положении ON, а у данного log-файла еще нет резервной копии. Блокировка с него может быть снята только с помощью команды "backup logs". Исполнение команды "backup snapshot" никак не отразится на блокировке этого log-файла.
Log-файлы, для которых была сделана резервная копия, должны регулярно удаляться вручную. Сохраняются только log-файлы, имеющие прямое отношение к BKP-файлу в области резервного копирования. Например, если в какой-то день создается резервная копия в виде моментального снимка, то все предыдущие резервные копии log-файлов могут быть удалены. Будьте внимательны: эти файлы могут занимать значительный объем дискового пространства.
Преимущество этого метода заключается в отсутствии необходимости прерывать работу пользователей, подключенных в этот момент к базе данных. Это особенно важно для операций, требующих круглосуточного доступа к базе данных. Формат резервного копирования в режиме онлайн имеет вид:
Существует два основных варианта резервирования в режиме онлайн. Первый соответствует использованию команды "backup snapshot" (закончен сам по себе), и второй - последовательному применению команд "backup database", "release log" и "backup logs" (они все необходимы для согласованного резервирования).
Независимо от выбранного варианта, резервное копирование состоит из следующей последовательности шагов:
Создание BKP-файла в избранной области резервного копирования (backup database);
- обновление самых последних log-файлов, поскольку в них содержится вся информация о текущем резервировании (release log);
- копирование всех надлежащих разблокированных log-файлов, предшествующих текущему log-файлу, в избранную область резервного копирования (backup logs).
В случае использования метода моментальных снимков (backup snapshot) все эти шаги выполняются автоматически.
При выполнении резервирования пунктом назначения данных может служить клиентский компьютер или сама сеть. Это указывается в ключе "directory-name" команды резервного копирования. Также необходимо хорошо представлять себе разницу между ключами "on server" и "on client" этой команды. При использовании ключа "on client" все данные и log-файлы будут помещены в указанный каталог определенного компьютера (даже если это сетевой сервер). Использование ключа "on server" приведет к резервированию прямо на сервере без предварительного сохранения данных на клиентском компьютере. Это может привести к значительному выигрышу в скорости резервного копирования и сокращению сетевого трафика!
Если используется ключ "on client", т.е. данные сохраняются на клиентском компьютере, каталог должен быть задан полным локальным путем либо в виде сетевого диска, например, C:\SQLBASE\BACKUPS\DB1 (локальный путь) или F:\BACKUPS\DB1 (сетевой диск). Однако, при применении ключа "on server" указываемый диск должен быть локальным для сервера, а не сетевым. Если используется сервер Novell, то путь к нужному каталогу должен быть указан в формате сервера Novell. Например, если резервное копирование базы данных производится в каталоге:
SERVER1\SYS:SQLBASE\BACKUPS\DB1
моментальный снимок базы данных DB1 может быть сделан следующим образом:
BACKUP SNAPSHOT FROM DB1 TO \SQLBASE\BACKUPS\DB1 ON SERVER;
Необходимо помнить о том, что не обязательно иметь доступ на запись или подключение к серверу или каталогу, где хранятся данные. Сервер может без всяких проблем сохранить резервные копии в своем корневом каталоге, если ему так было указано. Поэтому следует быть внимательными при задании их пункта назначения! Также не совершайте ошибку, помещая резервные копии в подкаталог самой базы данных. При удалении базы данных (перед восстановлением) удаляется весь ее каталог со всеми подкаталогами. В этом случае с резервными копиями можно распрощаться.
Создание моментальных снимков (команда backup snapshot) - самый простой метод резервного копирования баз данных. В этом случае копируются база данных и log-файлы, необходимые для восстановления базы данных до согласованного состояния. Перед резервированием log-файлов проводится их обновление, что позволяет включить в резервную копию текущий активный log-файл. В этом варианте резервного копирования требуется одна команда для резервирования данных и одна для их восстановления. Обычно этот метод применяется один раз вечером, перед резервным копированием сервера на магнитную ленту, и, может быть, один раз в течение дня. Недостаток этого метода заключается в том, что создание моментальных снимков очень большой базы данных может потребовать значительных затрат времени, и, кроме того, варианты восстановления ограничены возвращением базы данных в состояние на момент формирования последнего моментального снимка. Любые изменения, сделанные после данного снимка, будут потеряны.
Этот метод резервного копирования данных несколько более сложен, но гибкость восстановления стоит дополнительных усилий. Он требует резервного копирования файла базы данных, разблокирования log-файла (поскольку тот содержит информацию о текущей резервной копии), а затем резервирования log-файлов. Внимание! Никогда не делайте резервной копии только одной базы данных без log-файлов. Этот метод резервного копирования позволяет изредка резервировать базу данных вместе с ее log-файлами, после чего регулярно создавать резервные копии только одних log-файлов, например, несколько раз в день. Это позволяет провести восстановление базы данных, а затем использовать возможность "rollforward" log-файлов для восстановления работы, выполненной в течение дня. То, насколько часто создаются резервные копии log-файлов, зависит от объема доступного пространства на диске и от того, какое количество данных пользователь может себе позволить потерять. Заметим: накопление log-файлов может привести к очень быстрому заполнению диска. Такой подход особенно удобен для больших баз данных, поскольку резервное копирование файла базы данных, отнимающее много времени, выполняется редко, а периодическое создание резервных копий log-файлов можно выполнить достаточно быстро. Недостатком метода является скапливание log-файлов до их резервирования.
В прошлом любую базу данных SQLBase размера больше 2 ГБ было необходимо разбивать на части. Начиная с SQLBase версии 7.5.0, это ограничение было поднято для баз данных на всех операционных системах, за исключением семейства Novell. Теперь их размер может расти до 256 ГБ без необходимости разбиения. Впрочем, это ограничение действует только для DBS-файла, а не временных файлов или с расширением.bkp. Чтобы справиться с таким ограничением, был введен новый метод сегментированного резервного копирования.
Сконфигурируйте контрольный файл и положите в тот же каталог, где сохраняются резервные копии. Не нужно вносить какие-либо изменения в операторы резервного копирования или запущенные программы. Сервер SQLBase находит контрольный файл в целевом каталоге и сегментирует резервную копию соответствующим образом. Контрольный файл имеет расширение.bcf, а его имя совпадает с названием резервируемой базы данных. Для создания этого файла можно использовать любой редактор текстовых файлов (например, notepad.exe).
Контрольный файл имеет следующий формат:
FILEPREFIX префикс
DIR каталог, куда помещается резервная копия сегмента
SIZE размер в МБ
Можно указать несколько операторов DIR, чтобы разбить базу данных на сегменты, каждый из которых меньше 2 Гбайт. Заметим, что суммарный объем, задаваемый всеми операторами SIZE, должен быть достаточно большим, чтобы позволить сделать резервную копию всей базы данных. Например:
FILEPREFIX MIKE
DIR C:\BACKUPS\MIKE SIZE 1000
DIR C:\BACKUPS\MIKE SIZE 1000
DIR C:\BACKUPS\MIKE SIZE 500
позволяет создать три файла в каталоге C:\BACKUPS\MIKE:
MIKE.1 1 ГБ
MIKE.2 1 ГБ
MIKE.3 0,5 ГБ
Обратите внимание на то, что эти файлы создаются, только если база данных требует столько места. В приведенном выше примере, если бы размер базы данных составлял лишь 1,8 ГБ, то были бы созданы лишь два сегмента: MIKE.1 и MIKE.2 размером 1 ГБ и 0,8 ГБ, соответственно.
Можно использовать: предоставляемый компанией Gupta интерфейс SQLTalk для выполнения команд, показанных выше; продукт SQLConsole (использует вызовы C/API), чтобы планировать создание резервных копий; собственное программное обеспечение, которое при резервировании учитывает все возможные особенности конкретной системы, например, проводит проверку базы данных перед резервным копированием.
SQLConsole - Этот продукт поставляется компанией Gupta и, благодаря своим превосходным возможностям мониторинга, позволяет проводить по расписанию создание резервных копий, включая проверку базы данных и обновления статистики. Этот довольно сложный продукт обладает большим набором настроек для выполнения резервного копирования.
Выше были рассмотрены основные моменты и рекомендации по проведению резервного копирования в режиме онлайн. Сделаем их краткий обзор:
- Выполняйте проверку базы данных ("check database") перед ее резервированием. Если проверка обнаружила ошибки в базе данных, не записывайте ее резервную копию поверх неповрежденной копии.
- Если не предполагается создать моментальный снимок, проверьте последовательность резервного копирования, т.е. порядок следования команд ""backup database", "release log" и "backup logs".
- Чтобы сэкономить время, по возможности используйте ключ "on server"!
- При использовании ключа "on server" на сервере Novell, путь к целевому каталогу должен быть указан в формате сервера Novell, а не в виде сетевого диска.
- Не удаляйте НИКАКИЕ log-файлы из текущего каталога их хранения, задаваемого утверждением logdir= в конфигурационном файле сервера под названием sql.ini (или утверждение dbdir=, если logdir= не определено).
- Периодически удаляйте из области резервного копирования старые log-файлы, чтобы освободить пространство на диске. Не стирайте файлы, относящиеся к текущему BKP-файлу. Безопасным является удаление из области резервного копирования любых log-файлов, которые были созданы раньше текущего BKP-файла.
- Если параметр LOGBACKUP находится в положении ON и используется команда "backup snapshot", log-файлы не будут разблокированы. Чтобы добиться этого, выполните команду "backup logs".
- Не помещайте резервные копии в подкаталог самой базы данных.
- Если во время создания резервной копии в виде моментального снимка была произведена перезагрузка клиентского компьютера, то при попытке повторного резервирования базы данных может появиться сообщение о том, что резервное копирование уже находится в процессе выполнения. Это может произойти при подключении к серверу до завершения предыдущего сеанса. Возникшее затруднение можно преодолеть, завершив прерванный сеанс с помощью SQLConsole или перезапуска сервера SQLBase.
Преимущество резервного копирования в режиме оффлайн состоит в том, что резервируемые данные направляются непосредственно в архив. В этом случае можно получить значительную экономию пространства на диске, потому что объем, требуемый для хранения резервной копии, равен размеру исходной базы данных.
Для создания резервных копий DBS-файла базы данных и всех log-файлов из ее каталога, используйте команды или утилиты операционной системы (например, команду "copy" или средства ARCServe). Если параметр LOGBACKUP находится в положении OFF, log-файлы копироваться не будут. Однако, если он находится в положении ON, необходимо сообщить серверу SQLBase, были ли log-файлы резервированы или они останутся "блокированным". Это можно сделать с помощью команды "nextlog" из арсенала интерфейса SQLTalk от Gupta. Для этого требуется быть подсоединенным к базе данных. Используется следующий формат:
SET NEXTLOG [целое число]
Заданное число указывает следующий резервируемый log-файл. Например, если последними в архив были отправлены резервные копии 4.LOG и 5.LOG, нужно выполнить команду "set nextlog 6".
Недостаток резервного копирования в режиме оффлайн заключается в необходимости демонтажа базы данных или отключения сервера SQLBase. Это происходит из-за того, что с момента первого подключения сервер SQLBase выступает по отношению к базе данных в качестве абонента записи, и эта связь не разрывается до тех пор, пока не будет демонтирована база данных или отключен сервер. Это означает, что все пользователи должны быть отсоединены, чтобы демонтировать базу данных или отключить сервер SQLBase. Поиск подходящего времени или отсоединение пользователей, которые забыли завершить сеанс перед уходом с работы, могут превратиться в настоящую проблему!
Восстановление базы данных
Здесь описываются различные варианты восстановления базы данных до согласованного состояния на основе выбранных настроек резервного копирования.
Комплект восстановления состоит из резервных копий BKP-файла и связанных с ним log-файлов. BKP-файл бесполезен без ассоциированных log-файлов. Процесс восстановления, по существу, проходит в три этапа:
- Скопируйте BKP-файл в каталог базы данных.
- Скопируйте log-файлы в каталог базы данных.
- Запустите двухходовой (redo и undo) процесс rollforward (восстановление с повтором всех завершенных транзакций) в отношении нового DBS-файла.
Команда восстановления имеет следующий формат:

В случае использования команды "restore snapshot", дальнейшие действия не требуются, поскольку все этапы восстановления будут выполнены автоматически. При выборе варианта "restore database" после восстановления базы данных нужно выполнить команду "rollforward". Следует отметить, что, как и в фазе резервного копирования, при использовании ключа "on server" (при котором время восстановления значительно сокращается) на сервере Novell, путь к целевому каталогу должен быть указан в формате сервера Novell, а не в виде сетевого диска. Процесс rollforward заключается в восстановлении всех изменений, сделанных после резервирования базы данных, чтобы привести ее в согласованное состояние. Log-файлы содержат информацию обо всех транзакциях, как успешных, так и тех, для которых был произведен откат. В процессе rollforward обращение к log-файлам происходит дважды. Во время прохода "redo" SQLBase локализует начальную точку всех транзакций и применяет все успешные транзакции к данной резервной копии. В проходе "undo" происходит обращение всех транзакций, для которых производился откат. В конце процесса отката база данных находится в полностью согласованном состоянии без незавершенных транзакций. Команда "rollforward" имеет следующий формат:

При использовании команды "rollforward to backup" будет восстановлена вся работа, совершенная вплоть до момента создания резервной копии базы данных. Это эквивалентно исполнению команды "restore snapshot". При этом не восстанавливаются никакие дополнительные log-файлы, которые могли быть резервированы после создания исходной резервной копии.
Команда "rollforward to time" позволяет восстанавливать данные до определенного момента времени. Это очень хорошо подходит для отката значительного объема ошибочно сделанных изменений. Например, если какой-нибудь новый неосторожный программист удалил половину базы данных и зафиксировал это изменение, то ее можно восстановить до состояния на момент удаления с помощью резервной копии и процесса rollforward.
В результате команды "rollforward to end" обрабатываются все log-файлы с последовательными номерами, начиная с первого файла от момента создания резервной копии. В этом случае восстанавливается максимально возможный объем работы. После обработки последнего log-файла появится сообщение о том, что следующий log-файл не может быть найден. Это нормально! Просто выполните команду "rollforward end", чтобы завершить восстановление и процесс rollforward.
Обратите внимание, что необходимо иметь и последовательно использовать ВСЕ log-файлы, чтобы откат был успешным. Если какие-либо log-файлы потеряны, операция rollforward будет остановлена в ожидании пропущенных файлов. Если это возможно, можно применить команду "restore logs", чтобы сделать нужные log-файлы доступными, а затем использовать команду "rollforward continue", чтобы продолжить процесс. Если какой-то из необходимых log-файлов недоступен, примените команду "rollforward end" для завершения процесса. База данных будет восстановлена только с учетом последнего обработанного log-файла.
Пара советов, на что нужно обратить особое внимание при проведении восстановления базы данных:
- После завершения исполнения команды "restore snapshot" может появиться сообщение "cannot connect to the database" (не удается подключиться к базе данных). По существу, это проблема синхронизации. После завершения восстановления старая база данных удаляется, BKP-файл копируется из каталога резервного копирования в каталог базы данных и устанавливается. После этого процесс восстановления пытается подсоединиться к базе данных для обработки log-файлов. Если система загружена или сервер SQLBase слишком медленно работает, чтобы вовремя обработать сообщение об обновлении установки базы данных, процесс восстановления не может к ней подключиться. Решением этого затруднения является увеличение значения параметра CONNECTTIMEOUT в секции маршрутизатора (router) конфигурационного файла sql.ini. Этот параметр указывает время ожидания (в секундах) после неудачного подключения к серверу перед следующей попыткой соединения. Например, если для успешного подключения к базе данных нужно задать параметру CONNECTTIMEOUT значение 20, создайте в секции маршрутизатора строку со значением: connecttimeout=20.
- Наличие одного только BKP-файла без log-файлов означает большую проблему. Тем не менее, и в этом случае можно попытаться что-то сделать. Иногда это работает, но ничего нельзя гарантировать. Предположим, что база данных называется MIKE.BKP. Используя SQLTalk, выполните команду задания имени сервера (set server), а затем сделайте следующее:
RESTORE DATABASE FROM [путь к каталогу резервных копий] ON SERVER TO MIKE;
Появится сообщение <
ROLLFORWARD MIKE TO BACKUP; (Заметим, что "to backup" - похоже, единственная опция, которая может сработать)
Возникнет сообщение <
ROLLFORWARD MIKE TO BACKUP; (Да, исполните эту команду еще раз!) Будет выдано сообщение <
CONNECT MIKE 1 username/password;
Появится сообщение <
Проведите проверку базы данных (команда "check database"), чтобы узнать о ее состоянии.
Сценарии
Здесь сравниваются различные методы резервного копирования и возникающие в результате возможности восстановления.
Ниже приведены несколько сравнений различных методов резервного копирования, чтобы дать представление о требованиях к дисковому пространству и возможностях восстановления. Предполагается следующее: стандартный размер log-файла - 1 МБ, их отсчет начинается с 1.LOG, для всех log-файлов созданы шаблоны максимального размера и все транзакции завершены до создания резервных копий.

Если в этот момент произошел отказ системы, возможности восстановления будут доступны только для предыдущей резервной копии. Восстановление последних трех log-файлов транзакций невозможно, так как нарушена непрерывность последовательности log-файлов (файлы 1-7 в области базы данных были разблокированы, поскольку транзакции были завершены и не нуждались в восстановлении после сбоя или в откате).
После моментального снимка:
Область базы данных Область резервного копирования
Заметим, что файл 4.LOG из области резервного копирования предназначен для удаления, поскольку соответствующие ему транзакции включены в файл DB1.BKP, а создан он был раньше этого файла.

Заметим, что все log-файлы находятся в области базы данных до их резервирования командой "backup logs", даже если все транзакции были завершены.

Заметим, что log-файлы автоматически удаляются из области базы данных, поскольку для них уже были созданы резервные копии и нет незавершенных транзакций.

Если в этот момент произошел отказ системы, возможности восстановления доступны для самой последней транзакции путем восстановления BKP-файла, обработки сначала log-файлов 1-4 из области резервного копирования, а затем файлов 5-8 из области базы данных.
_____________________________________________
После завершения методов "release log" и "backup logs"

Заметим, что ни один log-файл из области резервного копирования не предназначен для удаления, поскольку они ВСЕ должны быть использованы вместе с DB1.BKP из той же области, чтобы сделать его согласованным с файлом DB1.DBS из области базы данных.

Заметим, что раз были созданы резервные копии базы данных и log-файлов, log-файлы 1-10 из области резервного копирования могут быть разблокированы, поскольку новый BKP-файл должен содержать все соответствующие транзакции, а дата и время их создания будут более ранними, чем у файла DB1.BKP.
Заключение
Тот, кому еще никогда не приходилось восстанавливать свои данные, может считаться счастливым человеком. Однако статистика утверждает, что иногда это приходится делать! Разрабатывайте свою стратегию восстановления данных уже сейчас, до того, как в этом возникнет реальная необходимость.
Одной из важнейших задач, которую должен постоянно выполнять администратор баз данных - это осуществление резервного копирования. Если что-то пойдет не так, то это задача именно администратора баз данных восстановить сервер и запустить его как можно быстрее. Потеря производительности или, что хуже того, потеря данных, может очень дорого обойтись предприятию.
При желании иметь актуальную резервную копию БД, возникает желание использовать конфигурацию дисков RAID, которая обеспечивает создание зеркала с целью защиты данных, но это не панацея. Массивы RAID являются только первой ступенью в деле обеспечения защиты данных от потери. В зависимости от конфигурации массива RAID, один или даже несколько жестких дисков должны выйти из строя, прежде чем произойдет безвозвратная потеря данных. Кроме того, использование дисков «горячей» замены и горячего резерва может быть использовано для того, чтобы сервер продолжал работать без отключения даже в случае выхода из строя жесткого диска. Ключевая вещь, которую вы должен понимать АБД, это то, что массивы RAID могут защитить данные в случае выхода из строя жестких дисков. А что произойдет, если будет ЧП (пожар, потоп, ограбление и т.д.)? Файлы базы данных окажутся, повреждены в результате ошибки программного обеспечения или аппаратного сбоя? Ну и наконец, что будет, если пользователь (или сам АБД) удалит по ошибки данные, которые вдруг потребуются в дальнейшем? Конфигурация RAID не сможет помочь в этих случаях.
Самое главное - администратор может всегда заменить сервер, но данные этого сервера восстановить чрезвычайно трудно, иногда просто невозможно.
Рассмотрим некоторые типы резервного копирования баз данных.
Сервер SQL поддерживает три вида резервного копирования: полное (Full), разностное или дифференциальное (Differential) и копирование журнала (Log). В дополнение к трем основным видам резервного копирования, которые работают со всей базой данных в целом, есть также несколько дополнительных типов резервного копирования, которые используются для копирования одного файла или группы файлов.
Полное резервное копирование (Full) - создает полную резервную копию всех экстентов базы данных. Если АБД будет восстанавливать базу данных, используя для этого полную резервную копию, потребуется только самый последний созданный им экземпляр. Однако, полное резервное копирование - самый медленный тип резервного копирования.
Дифференциальное резервное копирование (Differential) - создает резервную копию только тех экстентов, которые были изменены с момента последнего полного копирования. Если АБД будет восстанавливать базу данных, используя дифференциальную резервную копию, ему потребуется последняя полная резервная копия и последняя созданная им дифференциальная резервная копия. Дифференциальное резервное копирование осуществляется гораздо быстрее, но требует больше времени на восстановление, так как требует применение, как полной резервной копии, так и дифференциальной резервной копии.
Резервная копия журнала - создает резервную копию журнала транзакций с момента последней полной резервной копии или предыдущей копии журнала транзакций. АБД потребуется (или не потребуется) создавать резервные копии журнала транзакций в зависимости от используемой им модели восстановления. Если он будет восстанавливать базу данных, используя полное резервное копирование и копирование журнала транзакций, для восстановления ему потребуется последняя полная резервная копия и все (по порядку) резервные копии журнала транзакций.
Следует заметить, что резервное копирование обычно осуществляется при работающей (on-line) базе данных. Этот процесс называется «размытое резервное копирование», потому что он выполняется на протяжении некоторого отрезка времени. Если в процессе резервного копирования экстентов базы данных происходят какие-либо изменения, процесс копирования, безусловно, продолжается. Для поддержания целостности, полное и разностное резервное копирование фиксирует ту часть файла журнала транзакций, которая соответствует времени от начала и до конца резервного копирования.
Сервер SQL может выполнять резервное копирование в файл, расположенный на жестком диске, на сетевом диске, на устройстве с магнитной лентой.
Все изменения, сделанные в базе данных, обязательно фиксируются в журнале транзакций. В случае аварии (такой, как отключение электроэнергии или «синий» экран) журнал транзакций может быть использован для восстановления изменений базы данных. Кроме того, контрольные точки используются для записи всех страниц оперативной памяти на жесткий диск, тем самым уменьшая время, необходимое для восстановления базы данных. Итак, если в контрольной точке все страницы с данными записываются на жесткий диск, зачем нам необходимо хранить информацию о транзакциях? Отвечая на этот вопрос, нам придется говорить о моделях восстановления.
Каждая база данных, запущенная на сервере SQL может придерживаться одной из трех моделей восстановления: Полной (Full), Регистрации пакетных операций (Bulk_Logged) и Простой (Simple).
Модель полного восстановления предоставляет наибольшее число возможностей в случае повреждения данных. Если все транзакции заносятся в журнал, и используется режим полного восстановления, транзакции сохраняются в журнале до тех пор, пока не будет создана их резервная копия. Как только будет осуществлено резервное копирование базы данных, дисковое пространство, использовавшееся для хранения информации о транзакциях, становится свободным и затем может быть использовано для ведения журнала новых транзакций. Так как все транзакции вносятся в резервную копию, полное резервное копирование делает возможным восстановление базы данных в «заданной точке времени», используя только те транзакции, которые имели место до этого момента времени. Например, мы можем провести восстановление, используя полную резервную копию, а затем восстановить все копии журнала транзакций до определенного момента, прежде чем какие-то важные данные были удалены.
Если модель полного восстановления отслеживает все изменения, сделанные в базе данных, и позволяет нам восстанавливать все транзакции к любому моменту времени, то возникает вопрос - почему бы всегда не использовать эту модель? Так как все операторы должны при этом фиксироваться полностью, на выходе может получиться достаточно «тяжелый» файл журнала. Кроме того, такие команды как BULK INSERT будут замедлять работу сервера, так как все выполняемые ими изменения должны вноситься в журнал.
Модель регистрации пакетных операций (bulk_logged) достаточно похожа на модель полного восстановления с некоторые добавлениями и преимуществами. Как и в полной модели восстановления, в модели регистрации пакетных операций также фиксируются все операторы UPDATE, DELETE и INSERT. Однако, для определенных команд, в данной модели фиксируется лишь то, что операция имела место. Это верно для таких команд как BULK INSERT, bcp, CREATE INDEX, SELECT INTO, WRITETEXT и UPDATETEXT. Модель регистрации пакетных операций похожа на модель полного восстановления тем, что не использует повторно (не перезаписывает) пространство журнала до тех пор, пока не будет произведено резервное копирование всех транзакций.
В отличие от модели полного восстановления, если журнал транзакций содержал пакетные операторы, то вы не сможете осуществить восстановление на конкретный момент времени, вы должны восстанавливать ее только на конец всего журнала. Также резервная копия журнала базы данных может оказаться значительной по размерам, потому что в модели регистрации пакетных операций процесс резервного копирования журнала должен копировать все экстенты, которые были изменены.
Преимущества данной модели состоят в том, что файлы журнала транзакций для баз данных могут быть меньше, если вы используете много пакетных операторов. Кроме того, пакетные операторы выполняются быстрее, так как фиксироваться должен только факт, что выполнение этого оператора имело место, а не само изменение в базе данных.
Простая модель восстановления. В отличие от полной и модели регистрации пакетных операций, простая модель восстановления не использует резервное копирование журнала транзакций. В данной модели журналы транзакций часто усекаются (усечение - это процесс удаления старых транзакций из журнала) автоматически. Модель простого восстановления может использовать полное и разностное резервное копирование.
база данные администрирование документоведение